Assessment of Microsoft's Markitdown series 2:Parse PDF files


In a previous example, I also tested the markitdown library, where I tested tables of varying difficulty.If you want to understand how the markitdown library performs with tables, please refer to the previous example. In this next example, I will introduce how the markitdown library parses PDF files.Next, I will use the markitdown library to parse two different PDF files and analyze the parsing results.
PDF files are categorized into editable versions and scanned versions.
1、Installation, usage, and introduction of the Markitdown library
It presently supports:
- PDF (.pdf)
- PowerPoint (.pptx)
- Word (.docx)
- Excel (.xlsx)
- Images (EXIF metadata, and OCR)
- Audio (EXIF metadata, and speech transcription)
- HTML (special handling of Wikipedia, etc.)
- Various other text-based formats (csv, json, xml, etc.)
First, we’ll install the Markitdown library using pip.
pip install markitdown
You can download the source code from GitHub and install it. There are also simple examples of the API in GitHub.
2、Editable PDF
This example parses an editable PDF,I will analyze from the perspectives of title, formatting, and text order to see how markitdown functions with editable PDF files.
Let’s start parsing the PDF file.I have listed two pages of PDF content for comparison.


This is a function for writing to a markdown file.
import markdown
def write_markdown_to_file(markdown_text, output_file):
"""
Write Markdown text to a file.
Args:
markdown_text: A string containing Markdown formatted text.
output_file: The path to the output file.
"""
try:
with open(output_file, 'w', encoding='utf-8') as f:
f.write(markdown_text)
except Exception as e:
print(f"write file error: {e}")
This is the code test for the editable version.
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("Editable.pdf")
print(result.text_content)
write_markdown_to_file(result.text_content, 'Editable.md')
Since the file is relatively large, I will compare a few points to better observe the advantages and disadvantages of markdown parsing.


Here, we can see that there’s a deviation in the title. The font formats and title styles from the PDF are missing.

However, the footer in the PDF was also found, which is not bad.
The text order in the PDF is also from left to right, and markitdown performs very well in this aspect. However, our initial intention in converting the PDF to markdown text is to put this text into LLMs for RAG or other applications. So, it’s not really an issue, and it’s still quite good.
2、Scanned PDF
We have now compared the results of the editable version. Besides the style and title distinction in the text, no other text content is missing.
OK, next, let’s test the scanned version. This basically means we have to use OCR to parse the PDF file. We can then see how markitdown handles this type of PDF file.
Example of a scanned PDF.

Take the example code from the editable version, change the editable version file to the scanned version, and then output and view the results.
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("scanned.pdf")
print(result.text_content)
write_markdown_to_file(result.text_content, 'scanned.md')
Unfortunately, I encountered an error during use. It requires me to install the ffmpeg application library. After completing the installation, I executed the code block again, but it did not produce the corresponding results.
Markitdown returned an empty value for me.
3、 Formulas in PDF files
One aspect of PDFs that I’m particularly interested in is the formulas they contain.
Formulas are very difficult to parse. After testing several platforms, I haven’t found one that parses formulas particularly well. So, let’s test markitdown’s capabilities.
This is a screenshot of a formula from the PDF I used for testing.
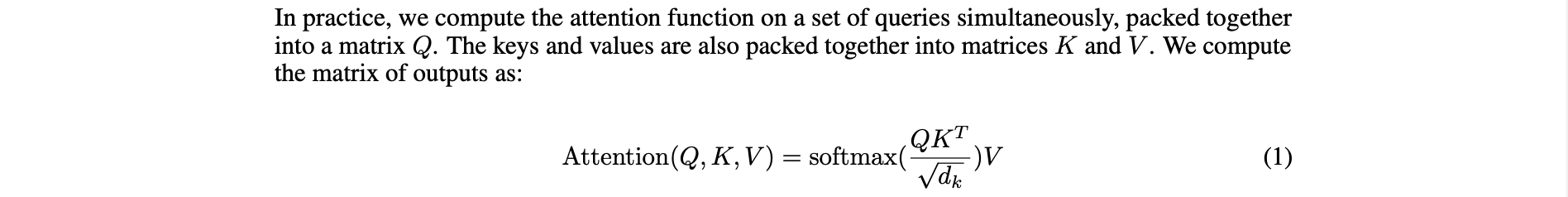
After changing the filename in the code and running it, the output result included the text of the formula above.
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V . We compute the matrix of outputs as:
Attention(Q, K, V ) = softmax(
QK T
√
dk
)V
(1)
1√
Although the text of the formula was found, the original formula format is lost, making it impossible to understand the meaning of the formula.This result is still not ideal.
4、Test Summary
After completing the tests, I found that if it’s an editable PDF, the markitdown library can parse it completely. From the current results, there are no issues with the text and images, but the text styles and formula parsing are not very accurate.
The parsing results for scanned PDF files are not ideal, which prevents me from using it extensively in current projects. I may test and use the markitdown library again in the future, as its mode and usage are very convenient. Therefore, I will continue to pay attention to it. Well, this concludes this test. Thank you for watching, and I look forward to bringing you better testing results next time.
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox