Assessment of Microsoft's Markitdown series 1:Parse PDF Tables from simple to complex


This blog will introduce to you how the Markitdown library parses Excel files containing tables of varying difficulty and then demonstrate it. I will parse files of varying difficulty one by one and review the parsing results.Before testing this library, I also used other file parsing libraries and have some experience. OK, let’s continue discussing this topic.
1、Determining table complexity
While testing various file parsing platforms, I’ve realized that table complexity influences parsing difficulty. Hence, I’ll test different levels of table complexity in this example.Currently, the easiest tables to parse are two-dimensional tables without any unusual structures.Many platforms I’ve tested have no issues with tables of this difficulty, but they encounter more or less problems when parsing more complex tables. For example, there can be discrepancies when parsing merged tables and pivot tables.
2、Installation, usage, and introduction of the Markitdown library
Markitdown is an open-source Python library developed by Microsoft. It is a utility tool for converting various files to Markdown (for instance, for indexing, text analysis and so on).
It presently supports:
- PDF (.pdf)
- PowerPoint (.pptx)
- Word (.docx)
- Excel (.xlsx)
- Images (EXIF metadata, and OCR)
- Audio (EXIF metadata, and speech transcription)
- HTML (special handling of Wikipedia, etc.)
- Various other text-based formats (csv, json, xml, etc.)
First, we’ll install the Markitdown library using pip.
pip install markitdown
You can download the source code from GitHub and install the library. There are also simple API examples available on GitHub as well.
3、Parse standard two-dimensional table
I will use the markitdown library to parse the structure of a two-dimensional table. The following image is a diagram of a two-dimensional table from a test Excel file. Below is the Python code I used for testing.
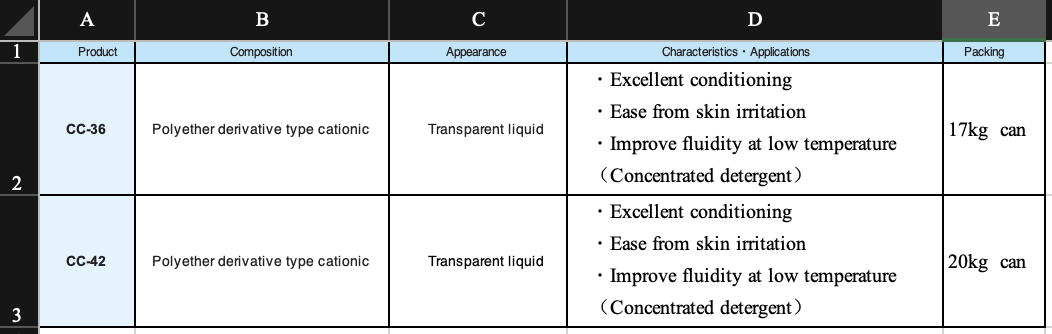
A function used for writing Markitdown text is defined as follows.
import markdown
def write_markdown_to_file(markdown_text, output_file):
"""
Write Markdown text to a file.
Args:
markdown_text: A string containing Markdown formatted text.
output_file: The path to the output file.
"""
try:
with open(output_file, 'w', encoding='utf-8') as f:
f.write(markdown_text)
except Exception as e:
print(f"write file error: {e}")
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("Two-dimensional.xlsx")
print("Two-dimensional:")
print(result.text_content)
Two-dimensional:
## Sheet1
| Product | Composition | Appearance | Characteristics・Applications | Packing |
| --- | --- | --- | --- | --- |
| CC-36 | Polyether derivative type cationic | Transparent liquid | ・Excellent conditioning\n・Ease from skin irritation\n・Improve fluidity at low temperature\n(Concentrated detergent) | 17kg can |
| CC-42 | Polyether derivative type cationic | Transparent liquid | ・Excellent conditioning\n・Ease from skin irritation\n・Improve fluidity at low temperature\n(Concentrated detergent) | 20kg can |
Call the function to write the markdown file, writing the text parsed by markitdown into the markdown file.
write_markdown_to_file(result.text_content, 'Two-dimensional.md')
The markdown text is as follows:
| Product | Composition | Appearance | Characteristics・Applications | Packing |
|---|---|---|---|---|
| CC-36 | Polyether derivative type cationic | Transparent liquid | ・Excellent conditioning\n・Ease from skin irritation\n・Improve fluidity at low temperature\n(Concentrated detergent) | 17kg can |
| CC-42 | Polyether derivative type cationic | Transparent liquid | ・Excellent conditioning\n・Ease from skin irritation\n・Improve fluidity at low temperature\n(Concentrated detergent) | 20kg can |
As you can see, Markitdown handles simple two-dimensional tables quite well and shows good performance.
4、Parse merge cells table
After testing the standard two-dimensional table, and being very satisfied with the results, next we’ll test a more complex table. Let’s begin the test with a merged table.
Below is the example image of the merged table I used.

Use the markitdown library to parse an Excel file with merged cells.
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("merge_cells.xlsx")
print("merge_cells:")
print(result.text_content)
merge_cells:
## Sheet1
| Product | Composition | Appearance | Applications | Solid content % | Packing |
| --- | --- | --- | --- | --- | --- |
| DM-30A | Cationic polymer | Slight yellowish liquid | ・Paper coating agent for paper of printer\n・Electric conductor for information paper | 30 | 18kg can\n200kg drum |
| DM-50 | NaN | NaN | ・Water resistant agent for paper | 40 | 200kg drum |
Call the function to write the markdown file, writing the text parsed by markitdown into the markdown file.
| Product | Composition | Appearance | Applications | Solid content % | Packing |
|---|---|---|---|---|---|
| DM-30A | Cationic polymer | Slight yellowish liquid | ・Paper coating agent for paper of printer\n・Electric conductor for information paper | 30 | 18kg can\n200kg drum |
| DM-50 | NaN | NaN | ・Water resistant agent for paper | 40 | 200kg drum |
As you can see, Markitdown handles simple two-dimensional tables quite well and shows good performance.
4、Parse merge cells table
After testing the standard two-dimensional table, and being very satisfied with the results, next we’ll test a more complex table. Let’s begin the test with a merged table.
Below is the example image of the merged table I used.

Use the markitdown library to parse an Excel file with merged cells.
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("merge_cells.xlsx")
print("merge_cells:")
print(result.text_content)
merge_cells:
## Sheet1
| Product | Composition | Appearance | Applications | Solid content % | Packing |
| --- | --- | --- | --- | --- | --- |
| DM-30A | Cationic polymer | Slight yellowish liquid | ・Paper coating agent for paper of printer\n・Electric conductor for information paper | 30 | 18kg can\n200kg drum |
| DM-50 | NaN | NaN | ・Water resistant agent for paper | 40 | 200kg drum |
Call the function to write the markdown file, writing the text parsed by markitdown into the markdown file.
| Product | Composition | Appearance | Applications | Solid content % | Packing |
|---|---|---|---|---|---|
| DM-30A | Cationic polymer | Slight yellowish liquid | ・Paper coating agent for paper of printer\n・Electric conductor for information paper | 30 | 18kg can\n200kg drum |
| DM-50 | NaN | NaN | ・Water resistant agent for paper | 40 | 200kg drum |
Okay, we can see that in the merged table, a row that was merged is missing, and two cell values are missing.According to my expected result, it should either output the table in its original format, or split the merged cells so that each row has the corresponding values of the merged cell.
5、Parsing complex table
Having tested merged tables and standard two-dimensional tables, next we will test even more complex tables.
Complex tables are irregular tables. The ones tested here will not be the most complex.
This is a basic information table for a box.

Use the markdown library’s interface to parse this complex table.
from markitdown import MarkItDown
markitdown = MarkItDown()
result = markitdown.convert("complex.xlsx")
print("complex:")
print(result.text_content)
complex:
## Sheet1
| Unnamed: 0 | Top | Unnamed: 2 | C01 / C02 | Unnamed: 4 |
| --- | --- | --- | --- | --- |
| NaN | Base | NaN | G69 / G73 | G11 / G18 |
| Misura(cm) | m³ | colli | USD | USD |
| 240x120x74h | 0.98 | 3 | 3192 | 3211 |
| 300x120x74h | 1.12 | 4 | 3785 | 3803 |
Call the function to write the markdown file, writing the text parsed by markitdown into the markdown file.
| Unnamed: 0 | Top | Unnamed: 2 | C01 / C02 | Unnamed: 4 |
|---|---|---|---|---|
| NaN | Base | NaN | G69 / G73 | G11 / G18 |
| Misura(cm) | m³ | colli | USD | USD |
| 240x120x74h | 0.98 | 3 | 3192 | 3211 |
| 300x120x74h | 1.12 | 4 | 3785 | 3803 |
Currently, the parsing of complex tables is as shown in the example.
6、Test Summary
Based on the results of the current tests, the parsing of standard two-dimensional tables is quite good. However, Markitdown’s performance in parsing more complex tables is less satisfactory. Thus, you can refer to this example if you want to use the Markitdown library to parse tables. I will also conduct tests on other file types later. Let’s keep following the progress of the Markitdown library. Thank you for reading, and please stay tuned for my future testing examples.
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- [Comparison-of-API-Services-Graphlit-LlamaParse-UndatasIO-etc-for-PDF-Extraction-to-Markdown]Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox