A Brief Look at the Homogenized Open-Source Document Parsing Framework - Docling


With the rise of Retrieval-Augmented Generation (RAG), more and more people have begun to focus on the effect of document structured parsing, and this field has become highly homogenized.
In this blog, we’ll briefly explore the technologies within the Docling PDF document parsing framework.
Methods
Layout Analysis Model
Docling employs a layout analysis model, which is an object detector used to predict the bounding boxes and categories of various elements on a given page image. Its architecture is derived from RT-DETR and has been retrained on the DocLayNet dataset. The inference relies on onnxruntime. As I’ve mentioned in previous articles, layout analysis heavily depends on scene data. Consequently, this model, trained only on the DocLayNet dataset, fails to meet the requirements of some common Chinese scenarios. Moreover, since it’s trained with RT-DETR, it has relatively large model parameters. As an alternative, one can adopt the previously open-source lightweight layout analysis model that supports fine-grained layout detection in Chinese scenarios like research reports containing paragraph information and academic papers.
(Address: https://github.com/360AILAB-NLP/360LayoutAnalysis)

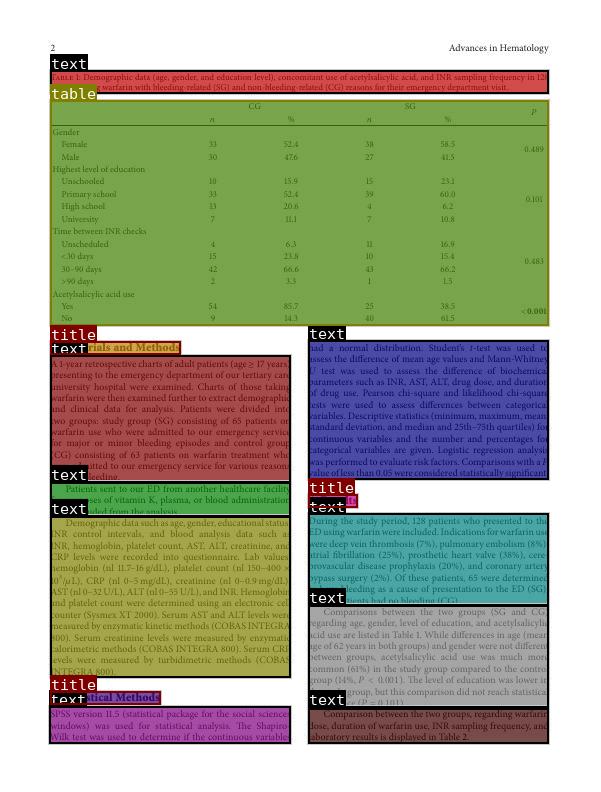
Table Structure Recognition Model
Secondly, Docling utilizes the TableFormer table structure recognition model. It can predict the logical row and column structures of a given table based on the input image. The inference depends on PyTorch.
OCR Text Recognition
Docling also offers optional OCR support, for example, for scanned PDF files. By default, Docling uses the EasyOCR engine, which performs OCR on high-resolution (216 dpi) page images to capture details of small fonts.
Processing Pipeline
Docling implements a linear processing pipeline that executes operations on each document in sequence. Each document is first parsed by the PDF backend to retrieve programmatic text markers and render a bitmap image of each page. Then, the standard model pipeline is independently applied to each page in the document to extract features and content such as layout and table structures. Finally, the results of all pages are aggregated and passed through a post-processing stage to enhance metadata, detect the document language, infer the reading order, and ultimately assemble a typed document object that can be serialized into JSON or Markdown.
Results
Processing Speed
On a MacBook Pro M3 Max, when using 4 threads, Docling’s solution time is 177 seconds, with a throughput of 1.27 pages per second and a peak memory usage of 6.20 GB. When using 16 threads, the solution time is 167 seconds, the throughput is 1.34 pages per second, and the peak memory usage is not recorded.
OCR Performance
By default, the OCR engine performs OCR on high-resolution page images, but it runs rather slowly (more than 30 seconds per page).
Resource Efficiency
On an Intel Xeon E5-2690, when using 4 threads, the solution time is 375 seconds, with a throughput of 0.60 pages per second and the peak memory usage not recorded. When using 16 threads, the solution time is 244 seconds, the throughput is 0.92 pages per second, and the peak memory usage is 6.16 GB.
Summary
Currently, intelligent document parsing is highly homogenized, and in fact, there are few practical tools that can effectively handle document parsing in specific scenarios. However, we can refer to the specific optimizations in the Docling project, such as multi-threading. By combining it with some other powerful open-source or self-developed small models and making replacements, we can build our own document parsing tools.
References
https://github.com/DS4SD/docling
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- [Comparison-of-API-Services-Graphlit-LlamaParse-UndatasIO-etc-for-PDF-Extraction-to-Markdown]Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox