A Comprehensive Assessment of Trieve PDF2MD for Intelligent Document Processing (IDP)


Today, we are going to present an evaluation of Trieve PDF2MD, in the context of Intelligent Document Conversion. In the modern digital age, the need to transform PDF files into more editable and manipulable formats has become increasingly crucial. Trieve PDF2MD claims to possess unique capabilities, especially with its OCR With Intelligence feature that can convert any PDF to LLM-ready Markdown using the thrifty vision models like GPT-4o-mini and Gemini-flash-1.5.
This evaluation will comprehensively assess its performance, functionality, and the value it brings to users in terms of efficient document transformation and enhanced text utilization. We will focus specifically on the experience and outcomes when using the GPT-4o-mini model throughout this assessment.
I. Highlights
Trieve PDF2MD offers several notable features that contribute to its value in document conversion:
- Fast Processing Speed: Trieve PDF2MD demonstrates impressive processing speed. It can convert an 18-page PDF with tables in approximately 40 seconds and an 11-page PDF with formulas in around 25 seconds. This rapid conversion rate enables users to handle document conversion tasks more efficiently and saves significant time in comparison to many other tools.
- Effective Equation Extraction: It shows a high level of proficiency in equation extraction. Whether it’s basic simple formulas, inline equations, or displayed equations, it can accurately parse and convert them into Markdown. This makes it a useful asset for users in fields such as mathematics, science, and engineering where equations are frequently encountered.
- Text Extraction from Multiple Formats: Trieve PDF2MD is capable of extracting text from a variety of document formats. It can handle the text extraction task with reasonable accuracy, although it may have some minor issues like occasional loss of paragraphs. Overall, it provides a convenient way for users to obtain text from different types of documents for further analysis or manipulation.
II. Limitations
Trieve PDF2MD, despite its strengths, also has certain limitations:
- Complex Table Recognition: While it can handle simple tables well, its performance in recognizing and parsing complex tables is lacking. It may misinterpret the structure of complex tables, such as merging two separate tables into one or providing inaccurate parsed results. This can be a hindrance for users who deal with highly detailed or intricately designed tabular data.
- Markdown Rendering Problems: There are issues with the Markdown it renders. Sometimes, the Markdown may have errors or not be in the most optimal format, which can affect the readability and further processing of the converted content. This may require users to manually correct or adjust the Markdown output.
- Occasional Formula Omission: Although it has good equation extraction capabilities, it may sometimes omit a part of a formula, especially in complex and long equations. This can lead to inaccuracies in the final converted document and may require users to double-check and fill in the missing parts. IBM Docling, while robust, faces challenges common to IDP tools. Users may encounter limitations in specific scenarios, particularly when dealing with highly complex documents. Despite its advanced AI models, Docling might struggle with intricate layouts or unusual formatting that deviate from standard document structures.
III. Comprehensive Evaluation of Trieve PDF2MD
1. Performance assessment
a.Processing speed
Trieve PDF2MD demonstrates relatively fast processing speed. For instance, when handling an 18-page PDF with tables, it only took around 40 seconds to process. And an 11-page PDF with formulas was processed in approximately 25 seconds (Cost: $0.06084 (Prompt) + $0.00550 (Completion) = $0.06634). Compared to some of the other tools evaluated previously, it shows a significant advantage in terms of speed, especially when using the GPT-4o-mini model. This rapid performance can enhance productivity and enable users to handle document conversion tasks more efficiently, saving valuable time in various workflows.
b.Resource usage
Trieve PDF2MD is designed to optimize resource usage while maintaining its high performance. During the testing process, it was observed that it did not cause excessive strain on the system resources. Even when dealing with complex PDFs, such as those with tables and formulas, it managed to operate smoothly without consuming an inordinate amount of memory or processing power. This efficient resource management makes it suitable for use on a wide range of devices, from standard desktops to laptops, without requiring users to worry about system slowdowns or the need for significant hardware upgrades.
2. Function assessment
a.Text extraction
Trieve PDF2MD has fairly decent text extraction capabilities. It is able to extract text from different document formats in most cases.
However, it does have some drawbacks. There are times when it may lose certain paragraphs during the extraction process. You can refer to the provided sample PDFs and the resulting Markdown renderings to observe such occurrences.
Moreover, another aspect that needs attention is that sometimes the Markdown it renders may have issues, which could potentially affect the subsequent usage and manipulation of the extracted text. This means that while it can serve as a useful tool for text extraction to some extent, users may still need to double-check and make necessary adjustments to ensure the accuracy and usability of the extracted content.
Sample PDF

Rendered Markdown

Sample PDF

Rendered Markdown
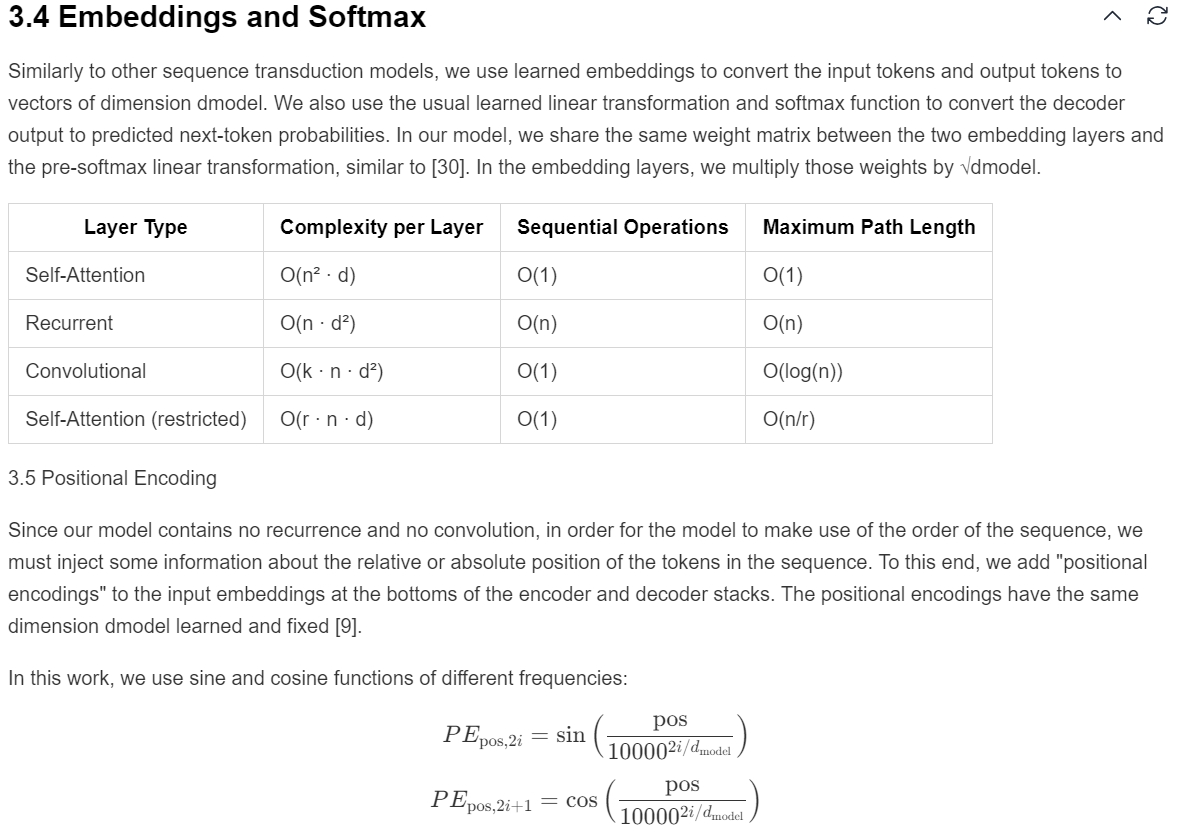
As shown in the sample picture above, it can be seen that a paragraph of text content is missing in the rendered Markdown file.
Sample PDF

Rendered Markdown

As can be seen from the sample picture above, there is a problem with the rendering of the subsequent paragraph in the rendered Markdown content.
b.Image extraction
For Trieve PDF2MD, since the images in the parsed Markdown cannot be displayed properly, we will not conduct an evaluation on this aspect in this assessment for now.
c.Table recognition
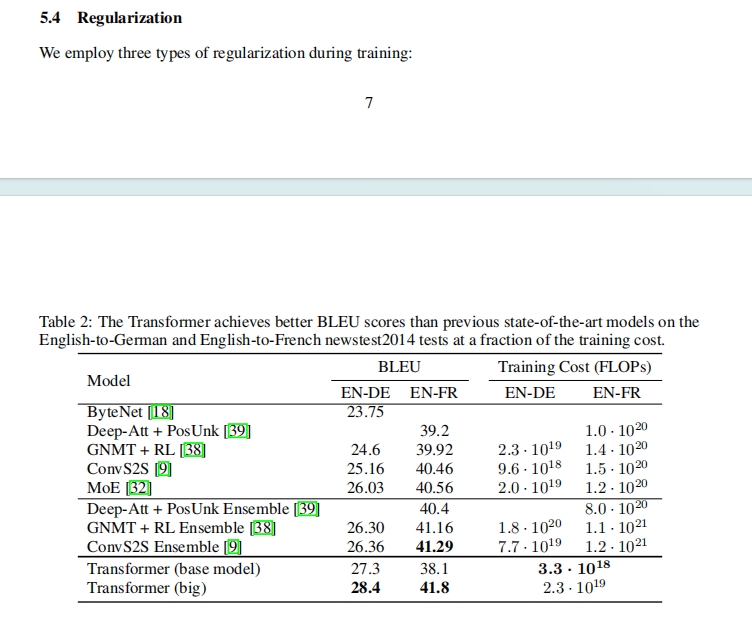
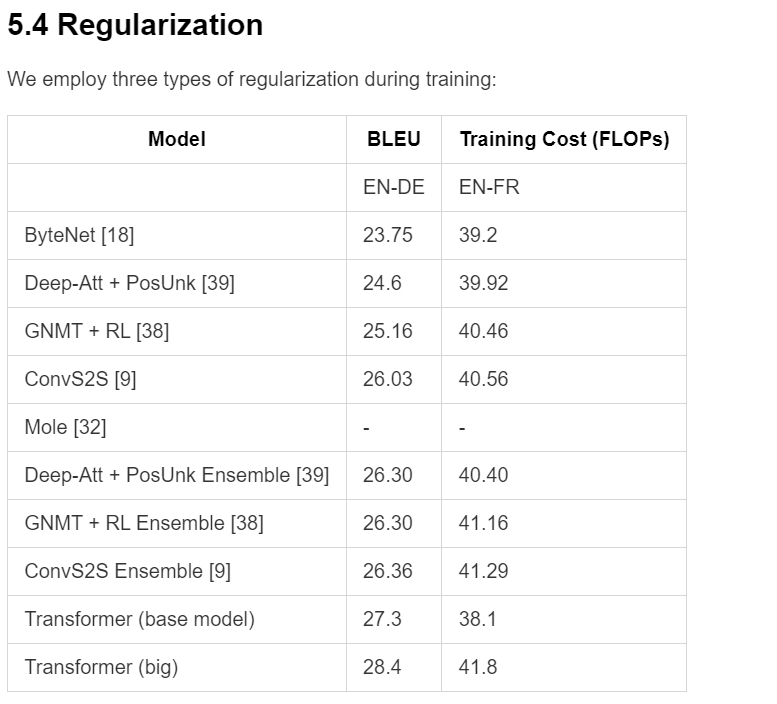
In this evaluation of Trieve PDF2MD, a wide variety of different types of tables were tested. It turns out that its ability to parse tables is also somewhat limited. When it comes to simple tables, it can perform quite well in parsing them.
However, its performance in handling complex tables is rather weak. In the last sample, for instance, it mistook two tables that were supposed to be in the same row as one single table. Moreover, the parsed results were not satisfactory in terms of content, failing to accurately present the information within the tables. This might bring difficulties for users who need to conduct comprehensive and precise processing of complex tabular information.
Sample PDF
Rendered Markdown
Sample PDF
Rendered Markdown
Sample PDF
Rendered Markdown
Sample PDF
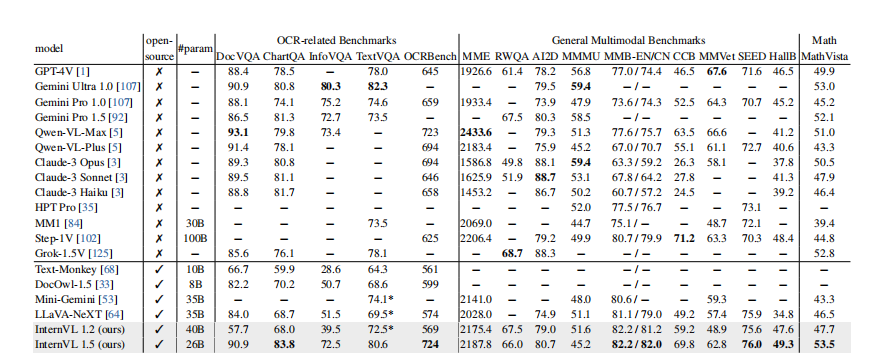
Rendered Markdown
Sample PDF
Rendered Markdown
d.Equation extraction
Trieve PDF2MD exhibits a remarkable aptitude for equation extraction. It proficiently handles basic simple formulas, whether they are inline or displayed equations, with a high degree of accuracy. In comparison to many other similar tools, its overall performance in equation recognition and conversion to Markdown is quite commendable. It manages to capture the essential elements of most equations, ensuring that the mathematical expressions are presented in a relatively clear and usable form.
Admittedly, it is not without a minor flaw. There are instances where a small portion of an equation might be omitted, such as in a complex formula where a particular term or symbol could be left out. Nevertheless, this slight imperfection does not significantly detract from its overall utility. It remains a valuable asset for those who require efficient extraction of equations from PDFs, as the vast majority of equations are processed correctly and can be readily utilized for further analysis or documentation purposes.
Sample PDF

Rendered Markdown

Sample PDF

Rendered Markdown

IV. Summary
Trieve PDF2MD presents a mixed bag of capabilities in the realm of Intelligent Document Conversion.
On the positive side, its processing speed is relatively fast. It can handle an 18-page PDF with tables in around 40 seconds and an 11-page PDF with formulas in about 25 seconds, which is quite impressive compared to some competitors. In terms of equation extraction, it generally performs well, accurately parsing basic simple, inline, and displayed equations, though it may occasionally miss a small part of a complex formula. It also does a decent job with text extraction from various document formats, despite sometimes losing certain paragraphs and having issues with Markdown rendering. For simple table recognition, it shows proficiency.
However, there are areas that need improvement. Its performance in handling complex tables is limited, as demonstrated by misidentifying two adjacent tables as one and providing unsatisfactory parsed results. Additionally, the problem with image extraction, where the images in the parsed Markdown cannot be properly displayed, led to its exclusion from evaluation in this aspect.
Overall, Trieve PDF2MD has the potential to be a useful tool for many document conversion tasks, especially those involving text and simple formulas. But for users with more complex requirements, such as dealing with intricate tables or relying heavily on accurate image extraction, they may need to consider supplementary tools or exercise caution when using Trieve PDF2MD. Future updates and enhancements could potentially address these limitations and further solidify its position in the market of intelligent document conversion tools.
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox