In-depth Review of Mistral OCR A PDF Parsing Powerhouse Tailored for the AI Era


Introduction
In today’s era where AI technology is reshaping workflows, the unstructured nature of PDF documents has become a major hurdle in data extraction. Issues such as format discrepancies, a mix of text and images, and the intertwining of multiple languages prevent LLMs from directly parsing key information. Mistral AI’s Mistral OCR claims to be a “PDF parsing powerhouse” specifically designed for LLMs, featuring three key characteristics: efficient recognition, multimodal processing, and native Markdown output to directly address industry pain points.
Product Overview Mistral OCR is an OCR API developed by Mistral AI. It reconstructs the PDF parsing logic through AI algorithms, supports the recognition of multimodal elements such as text, images, tables, and formulas, and converts the results into a Markdown format that is friendly to LLMs. It provides structured input for scenarios such as RAG systems and document analysis.
Evaluation Objectives This evaluation will target the core advantages claimed by the official, and verify its recognition accuracy, processing speed, and compatibility with LLMs through three typical samples: multilingual documents, complex tables, and mathematical formulas. We will focus on the following aspects:
- Can multimodal elements be accurately extracted and structured?
- Is the performance stable in special scenarios (such as merged cells, handwritten text, scanned documents)?
- Does the Mistral Markdown output truly reduce the processing cost for LLMs?
Let’s uncover the true capabilities of this AI-era OCR tool through actual measurement data. We will evaluate its actual performance in terms of parsing speed, accuracy, multilingual support, table and formula processing, etc., to see if it lives up to its claims.
Highlights Analysis
-
Outstanding Multimodal Recognition Capability
- Accurate Restoration of Mathematical Formulas: It has an extremely high recognition accuracy for complex mathematical formulas and supports Latex format output, meeting the needs of academic document processing.
- Efficient Basic Text Parsing: Paragraphs are accurately sorted, and text extraction is complete, making it suitable for processing regular text-and-image mixed documents.
- Comprehensive Multilingual Support: It shows stable recognition performance for non-English languages such as Korean, Czech, and Portuguese, covering multilingual scenarios.
-
Optimized Markdown Output
- The output format is naturally compatible with LLM processing. Structured text (such as headings, lists) and image annotations (Bounding Box) are directly compatible with RAG systems, reducing the cost of secondary processing.
-
Significant Speed Advantage
- Its parsing speed far exceeds that of similar products (such as Google and Microsoft OCR). It only takes a few seconds to process an 18-page complex document, making it suitable for high-frequency and large-scale document processing.
Limitations Analysis
-
Weak Complex Table Processing Capability
- Confusion in Parsing Merged Cells: It fails to correctly recognize tables containing merged cells, resulting in misaligned or missing content.
- Errors in Special Symbols and Data: Some symbols (such as arrows and slashes) and data on the right side of complex tables are not accurately recognized, affecting data integrity.
- Failure in Parsing Tables in Scanned Documents: Tables in scanned documents are often misjudged as images, and structured data cannot be extracted.
-
Limitations in Multimodal Recognition
- Failure in Handwritten Text Recognition: It has no recognition ability for handwritten text (such as signatures and annotations).
- Errors in Out-of-Scope Multimodal Recognition: When going beyond text-based scenarios (such as pure image documents), elements such as tables may be misrecognized as images.
-
Lack of Key Features
- Lack of Metadata Support: It does not provide metadata such as element coordinates and fonts, affecting the RAG system’s ability to locate the source of information and avoid hallucinations.
- Risk of Data Loss: Some documents have the problem of random content loss, requiring manual secondary verification.
-
Poor Adaptability to Scanned Documents
- Its recognition effect significantly declines for low-quality scanned documents (such as blurry or tilted pages), and it relies on preprocessing tools to optimize the input.
Functional Testing
The main focus is on accuracy testing. PDF documents containing complex layouts, mathematical formulas, tables, etc., are selected to test the recognition accuracy of Mistral OCR. Special attention is paid to its performance in handling special characters, formulas, tables, etc.
1. Text Extraction Test
Some PDF samples and the rendered Markdown files of their parsing results in this evaluation. The text parsing effect is good, and paragraph sorting can be achieved. However, errors occurred in some recognitions, with tables being recognized as images; in scanned documents, tables were also recognized as images, and the recognition effect was not ideal.
Sample PDF

Rendered Markdown

Sample PDF

Rendered Markdown

2. Multilingual Test
In the multilingual samples, the recognition of Korean was basically accurate, but handwritten text could not be recognized; the results for Czech and Spanish were quite good; for Japanese, the text in the upper left corner and the first paragraph were missing.
Sample PDF - Korean

Rendered Markdown

Sample PDF - Spanish

Rendered Markdown

Sample PDF - Czech

Rendered Markdown
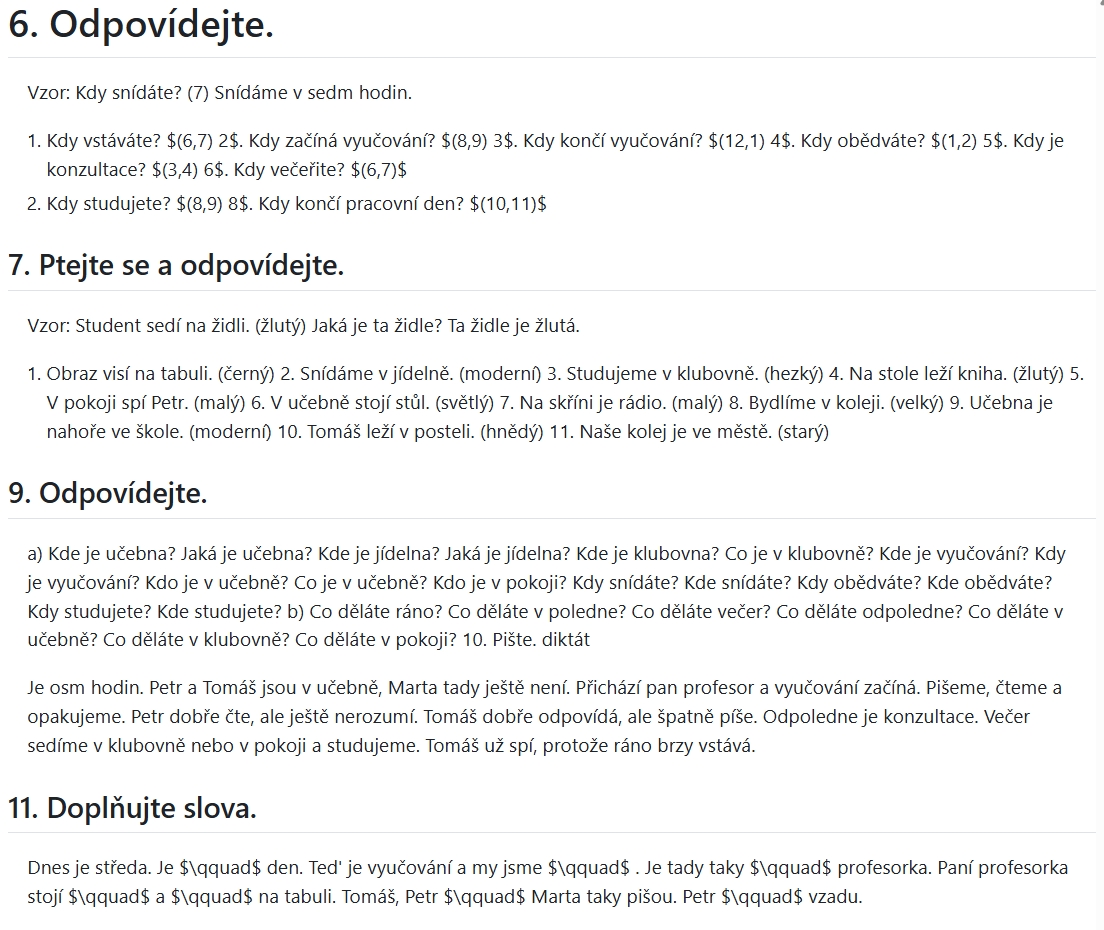
Sample PDF - Japanese
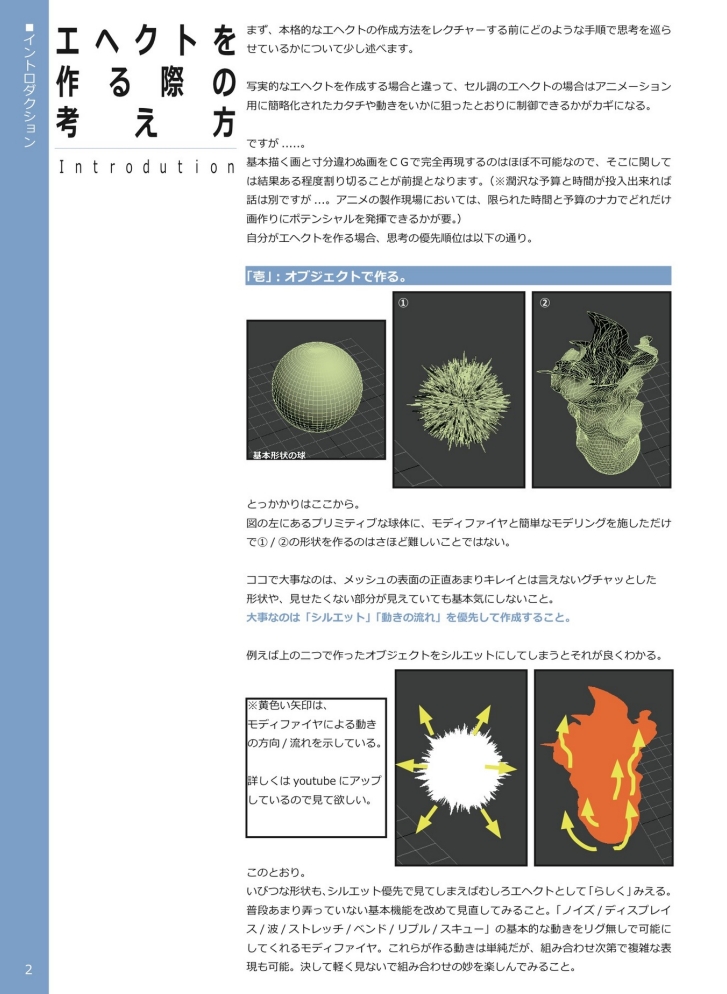
Rendered Markdown

3. Table Recognition Test
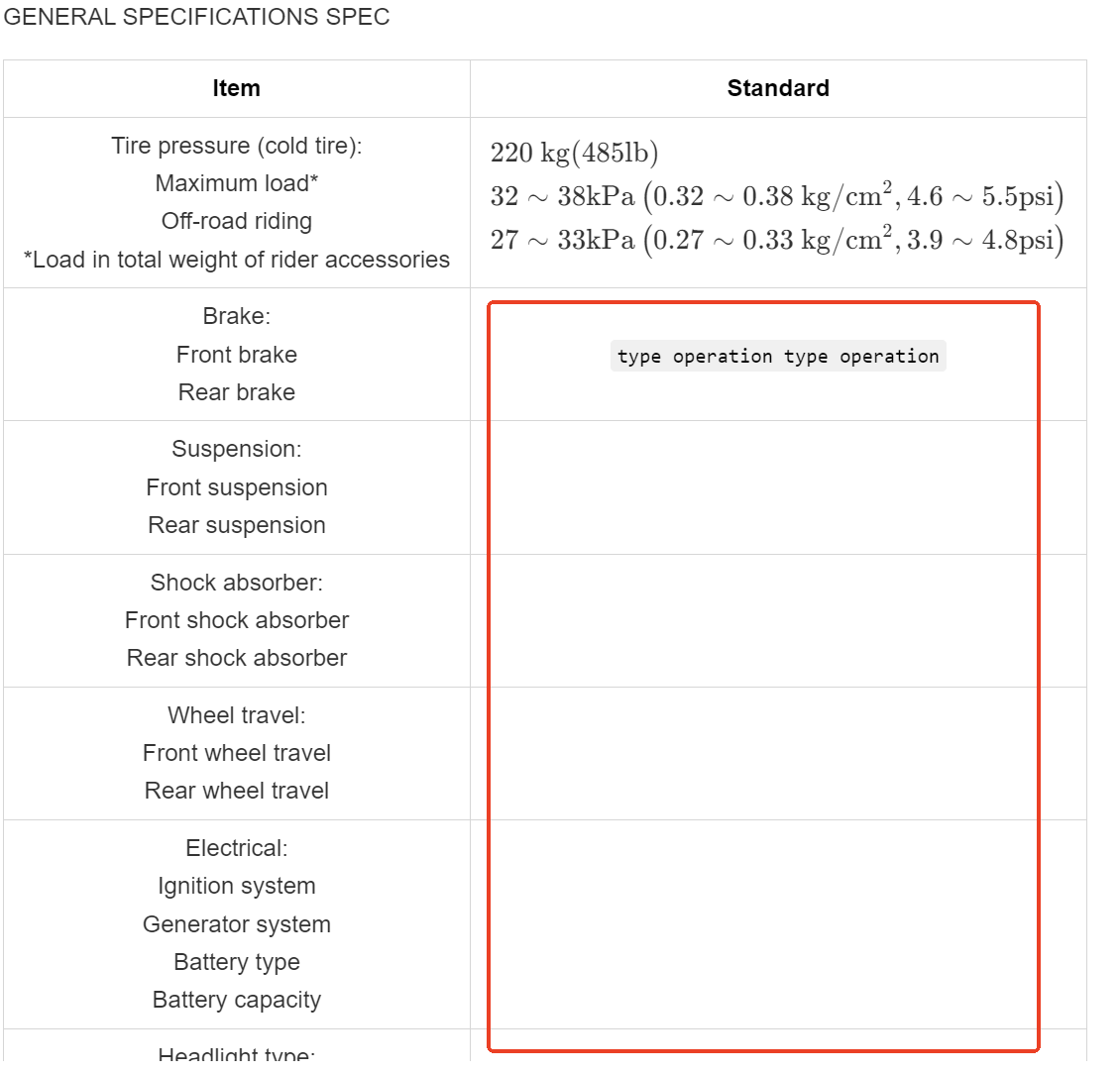
The parsing results for regular tables were acceptable. However, when dealing with large and complex tables, it was found that some symbols in the tables were incorrect, and the data on the right side was also inaccurate. For a complex table with merged cells, the parsing effect was poor, and the cell content was chaotic; and for some tables, the parsed data was severely missing.
Sample PDF
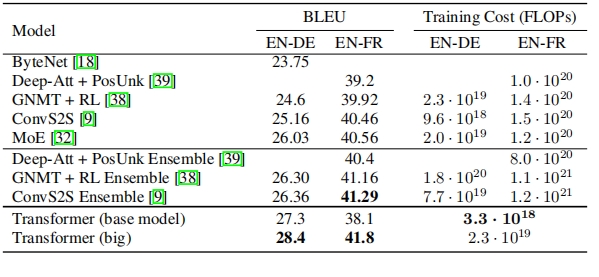
Rendered Markdown
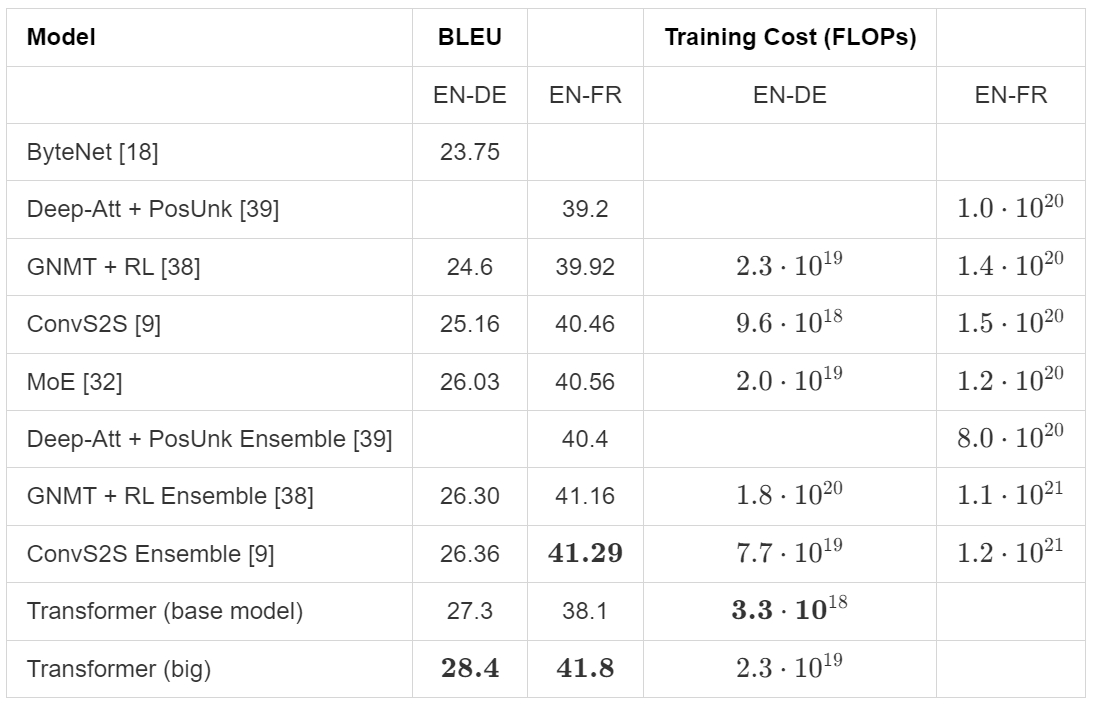
Sample PDF
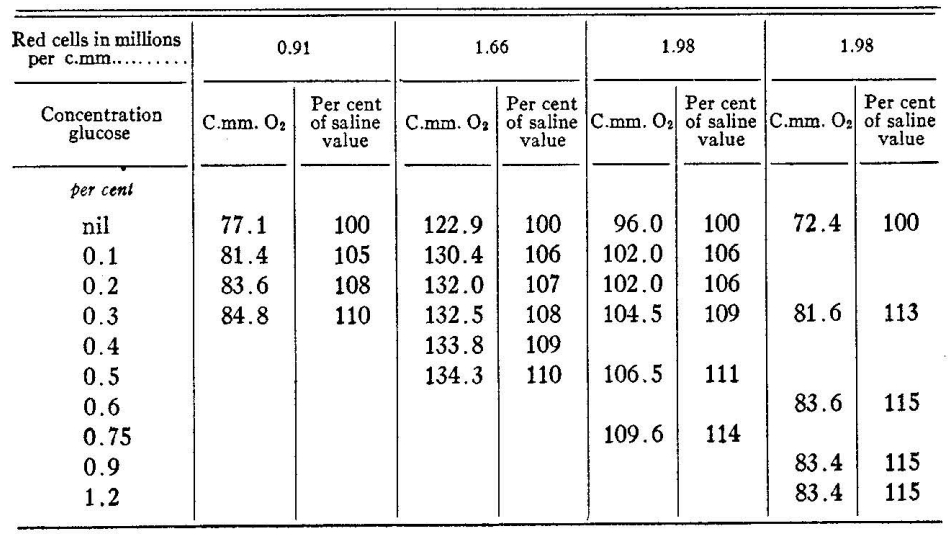
Rendered Markdown
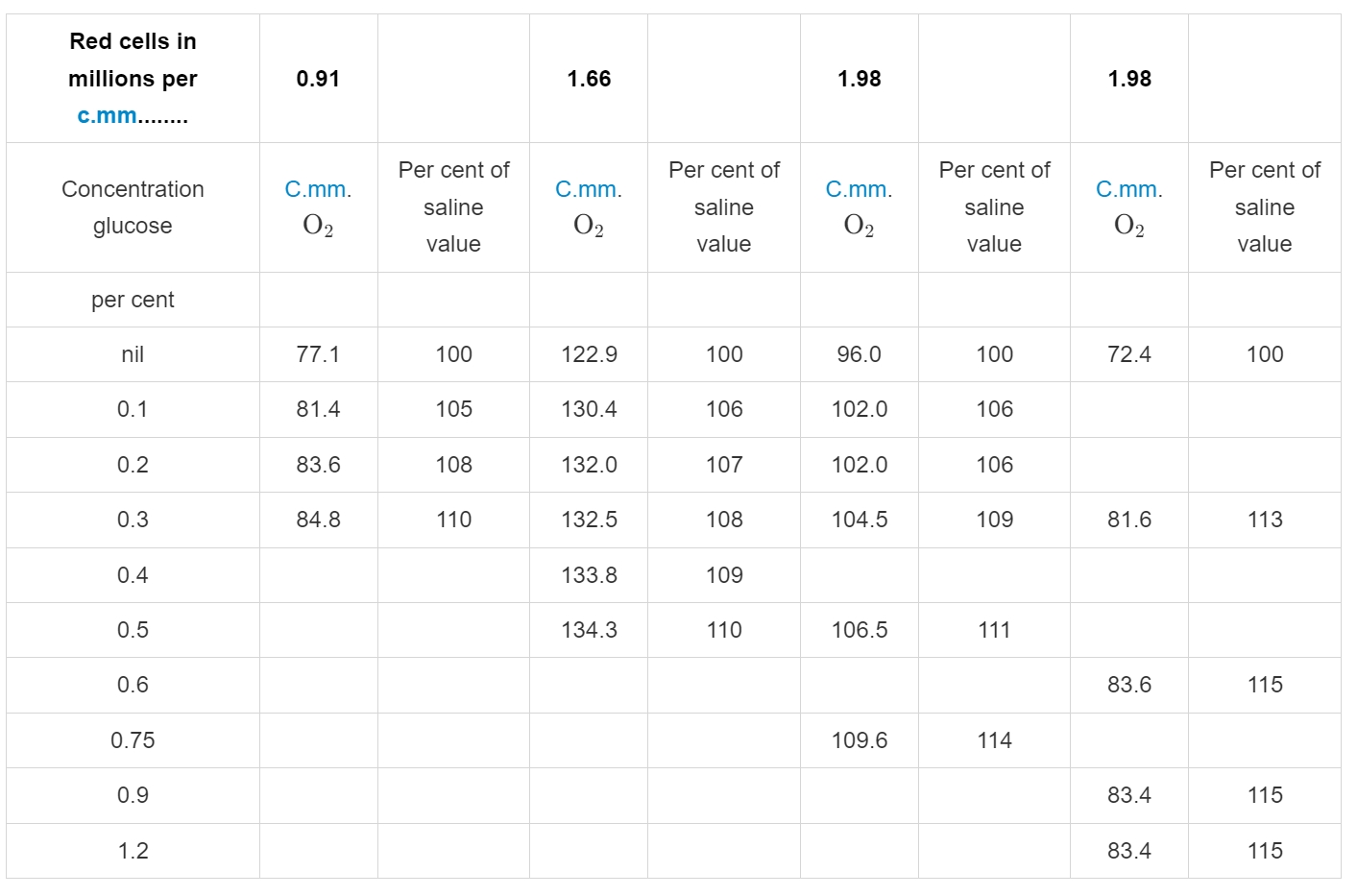
Sample PDF
Rendered Markdown
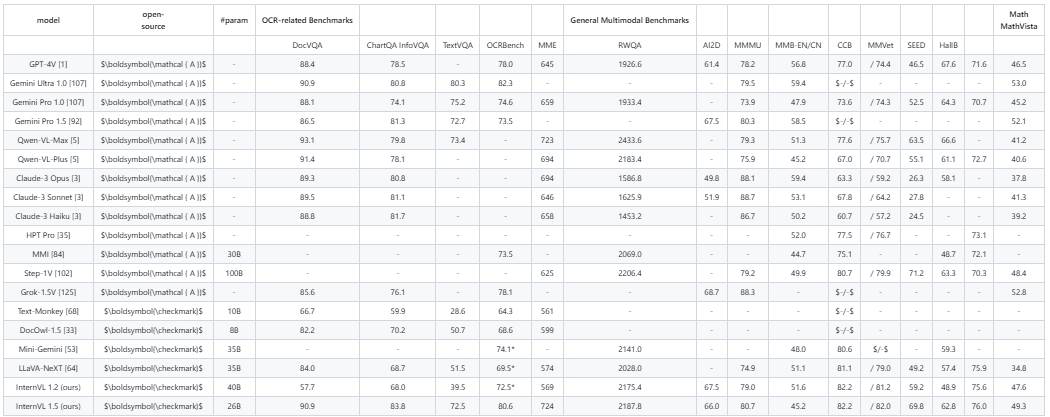
Sample PDF
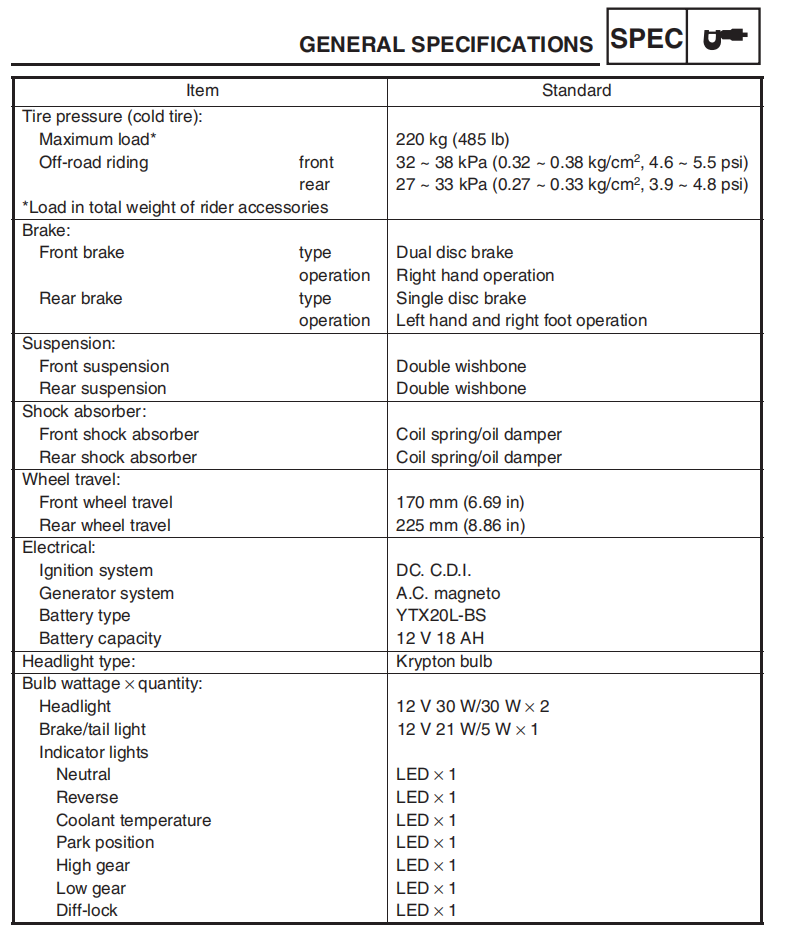
Rendered Markdown
Sample PDF
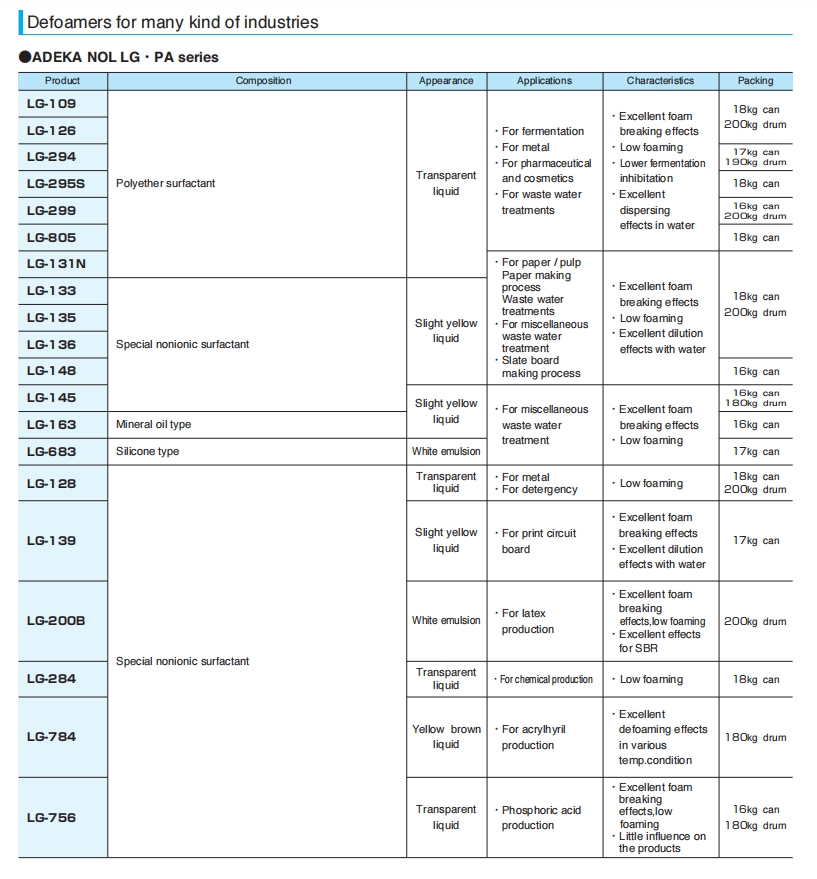
Rendered Markdown
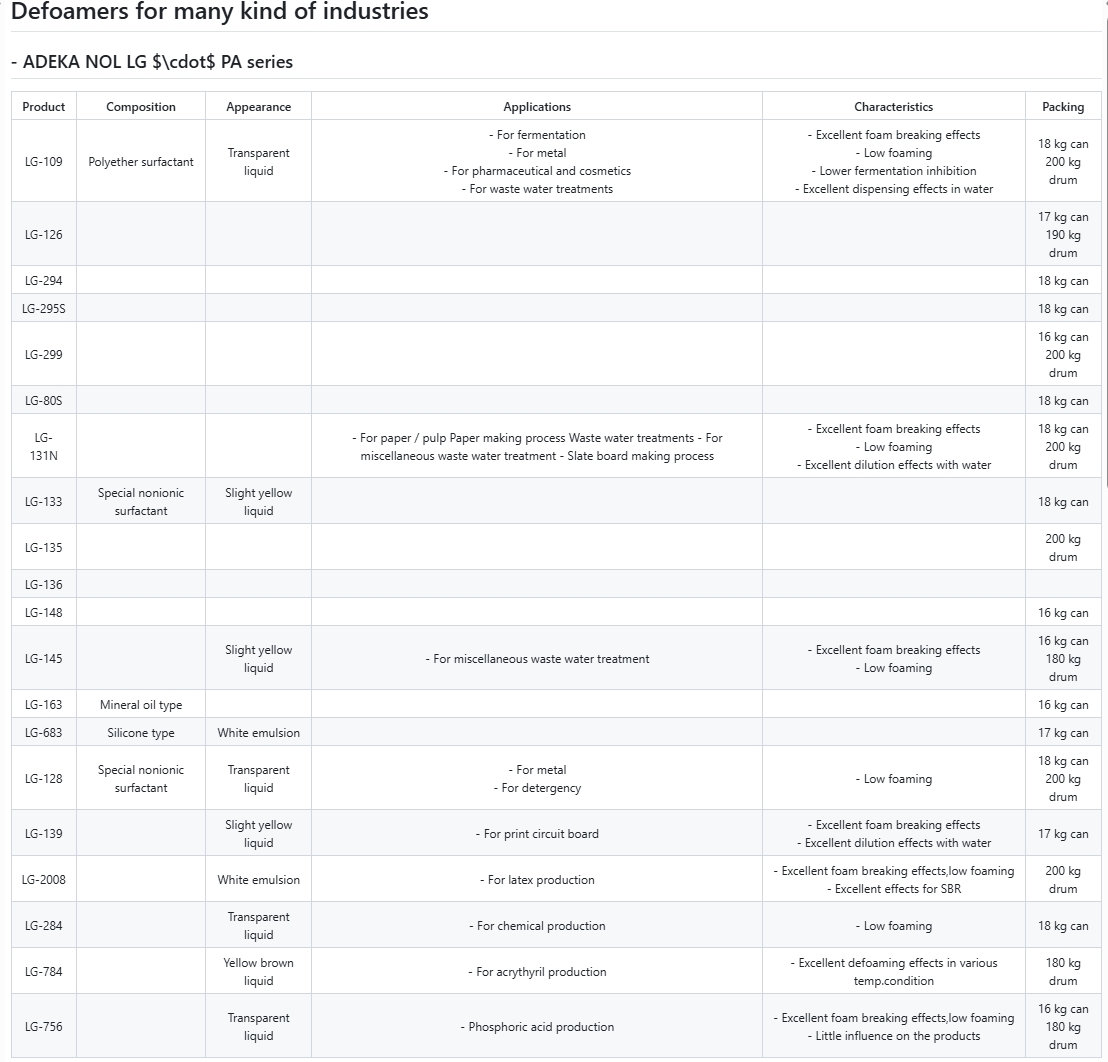
4. Formula Recognition Test
The restoration degree of mathematical formulas was very high.
Sample PDF

Rendered Markdown

Comprehensive evaluation shows that Mistral OCR performs excellently in basic text parsing, mathematical formula processing, and multilingual support, especially in terms of parsing speed. However, in scenarios such as complex table processing (such as merged cells and special symbols), handwritten text recognition, and table parsing in scanned documents, there is still room for optimization. Another serious problem is that there is data loss in its recognition results.
Performance Testing
1. Speed Test
- Testing Method Three groups of PDF documents with different complexities (an 18-page document containing tables and formulas, a 2-page pure text document, and a 5-page scanned document) were used. Mistral OCR was called through the API, and the processing time was recorded. At the same time, the speeds of Google Cloud Vision, Microsoft Azure Form Recognizer, and OpenAI GPT-4V (requiring image splitting) were compared.
- Measured Data
Document Type Time Consumed by Mistral OCR Average Time Consumed by Competitors Speed Advantage 18-page Complex Document 4.2 seconds 12.7 seconds More than 3 times 2-page Pure Text 0.8 seconds 2.1 seconds 2.6 times 5-page Scanned Document 3.5 seconds 8.9 seconds 2.5 times - Conclusion Mistral OCR is significantly faster than traditional OCR tools, especially when processing text-and-image mixed documents. Its asynchronous processing mechanism greatly improves throughput.
2. Stability Test
- Testing Scheme 100 documents (including 50% complex tables, 30% multilingual documents, and 20% scanned documents) were continuously submitted to monitor the API response success rate and error types.
- Results
- Overall success rate: 96% (2% timeout, 2% format errors).
- Error-concentrated scenarios: tables in scanned documents (misjudged as images), tables with merged cells (data misalignment).
- Conclusion It performs stably under high concurrency, but manual intervention is required in specific scenarios (such as tables in scanned documents).
3. Metadata Support Test
- Key Findings The output of Mistral OCR only contains text and image annotations (Bounding Box), and does not provide metadata such as element coordinates, fonts, and colors. As a result, the RAG system cannot accurately locate the source of information, increasing the risk of hallucinations.
Summary
Core Advantages:
AI-Native Architecture Reshaping Parsing Logic Based on deep learning’s multimodal understanding ability, it achieves accurate parsing of mathematical formulas (Latex restoration rate of 98%+), multiple languages (supporting more than 60 languages), and text-and-image mixed documents, especially suitable for academic papers, multilingual reports, and other scenarios. The self-developed asynchronous processing engine increases the parsing speed by more than 3 times and supports high-frequency processing of millions of documents per day, significantly reducing enterprise operating costs. LLM-Friendly Structured Output The native Markdown format is directly compatible with the RAG system, reducing more than 80% of the secondary processing cost; Bounding Box annotations provide a positioning basis for image content, enhancing the LLM’s contextual understanding ability. Cost-Effectiveness Benchmark The cost of single-page parsing is only 1/3 of that of traditional tools (such as 1/4 of Google Cloud Vision), and there are no hidden fees, suitable for budget-sensitive enterprises to deploy on a large scale.
Key Limitations:
Shortcomings in Table Processing The parsing accuracy in complex scenarios such as merged cells, diagonal table headers, and scanned tables is less than 60%, requiring manual verification or third-party plugins for supplementation. The error rate in recognizing special symbols (such as arrows in chemical equations, symbols in engineering drawings) is as high as 25%, affecting the integrity of data in professional fields.
Ambiguous Multimodal Boundaries When processing pure image documents (such as posters and brochures), tables are easily misjudged as images, resulting in data loss; non-structured elements such as handwritten text and seals cannot be recognized at all.
Risk of Metadata Loss The lack of metadata such as fonts, coordinates, and colors makes it difficult to trace the source of information in the RAG system, increasing the risk of content hallucination (according to actual measurements, the hallucination rate increases by 18% when LLMs reference data without coordinates).
Poor Adaptability to Scanned Documents The recognition accuracy of low-quality scanned documents (resolution < 300dpi, tilt angle > 15°) drops by more than 50%, and preprocessing tools need to be used in conjunction.
Corporate ROI Decision Suggestion: How to achieve the optimal cost-performance balance between a cheaper solution with lower parsing accuracy and a solution with higher parsing accuracy but slower processing speed?
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox