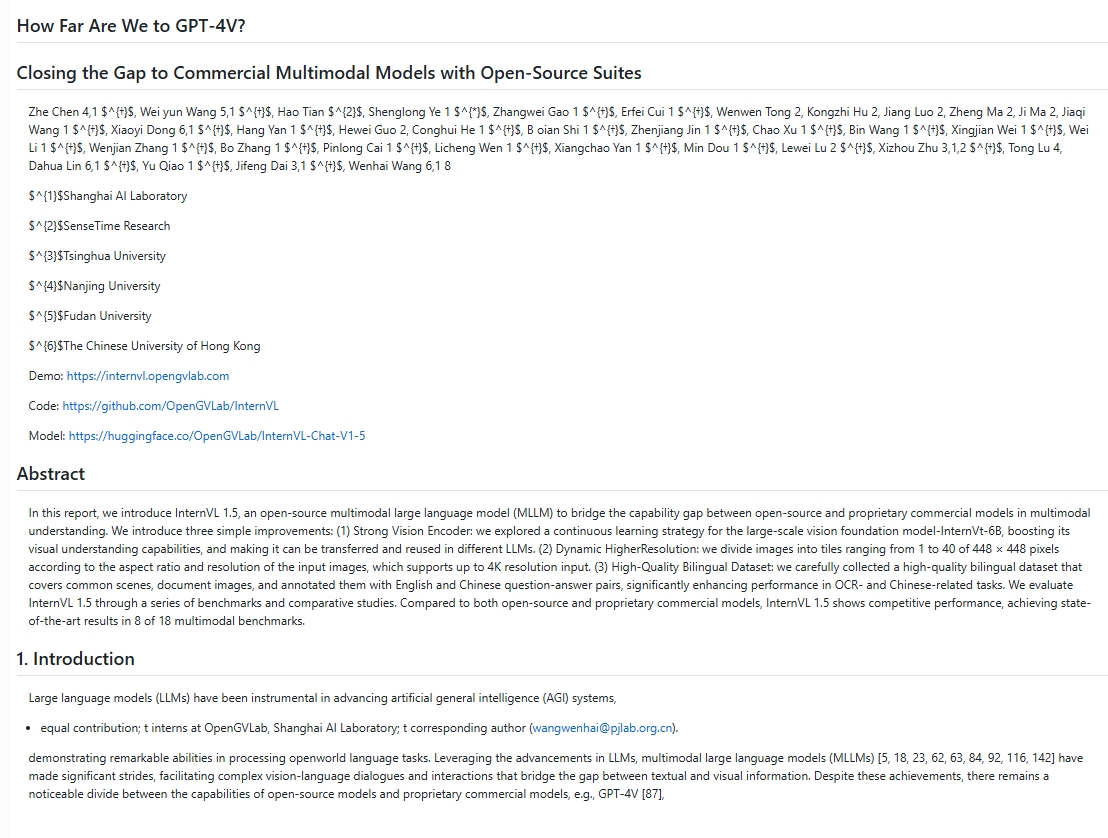
Is SmolDocling-256M an OCR Miracle or Just a Pretty Face? An In-depth Review Reveals All!


Introduction
In the age of AI-driven transformation, extracting data from unstructured image documents has become a significant challenge. Issues such as format variations, the combination of text and images, and multilingual content prevent large language models (LLMs) from directly parsing key information. SmolDocling-256M claims to be a powerful OCR tool designed to address these industry pain points with features like efficient recognition, multimodal processing, and the ability to output structured data.
Product Overview
SmolDocling-256M is an open-source OCR tool that uses advanced algorithms to reconstruct the image parsing logic. It supports the recognition of multimodal elements such as text, images, tables, and formulas, and aims to convert the results into a format friendly to LLMs, providing structured input for RAG systems and document analysis.
Evaluation Objectives
SmolDocling-256M, as promoted on its official website, claims to be a revolutionary OCR tool with enhanced capabilities in various domains. This evaluation is designed to rigorously test these assertions. The official site highlights its prowess in handling diverse document types, advanced parsing algorithms for complex structures, and broad multilingual support.
We will use three representative sample types-multilingual images, complex tables, and mathematical formulas-to evaluate the following key aspects:
- Multimodal Element Extraction and Structuring: Given SmolDocling-256M’s claim of advanced multimodal processing, we will check if it can accurately extract text, tables, and other elements from different types of documents and structure them in a meaningful way. For example, can it separate text from embedded images in a multilingual document and present them in an organized format?
- Performance in Special Scenarios: The official website implies stable performance across different scenarios. We will test its performance in special cases such as merged cells in tables, formulas within documents, and scanned images. This will determine if it can maintain high-quality results when faced with the challenges these scenarios present.
- LLM Compatibility and Processing Cost Reduction: Since the tool is said to be LLM-friendly, we will verify if its output can truly reduce the processing cost for LLMs. This involves checking if the parsed data is in a format that can be easily consumed by LLMs, thereby streamlining the overall processing pipeline.
By gathering actual measurement data on parsing speed, accuracy, multilingual support, and table and formula handling, we aim to objectively determine whether SmolDocling-256M lives up to the high-performance standards set by its official claims.
Highlights Analysis
- Acceptable Basic Text Parsing
- SmolDocling-256M shows an acceptable performance in basic text extraction from images. In normal text-image combinations, it can extract text with a relatively high success rate.
- Fair Standard Table Recognition
- For simple and standard tables, the model can recognize the basic structure correctly and extract most of the data, achieving a reasonable level of performance.
- Solid Western Language Handling
- When handling Spanish and Czech, the recognition is quite accurate, making it suitable for Western-language document processing.
Limitations Analysis
- Text Parsing Order Problem
- While the text is recognized, the order of the parsed text is incorrect. This can cause confusion, especially when dealing with long passages.
- Ineffective Scanned Image Recognition
- Scanned images pose a significant challenge. Tables in scanned images are often not recognized, and text recognition accuracy drops substantially.
- Weak Multilingual Capability
- Multilingual support is lacking. Japanese text comes out as garbled, and Korean text is incompletely parsed, missing key parts.
- Incapable Complex Table Processing
- Complex tables, especially those with merged cells or intricate headers, are not well-handled. Headers are mis-parsed, merged-cell content is jumbled, and exponential data in tables is difficult to parse.
- Inefficient and Inaccurate Formula Parsing
- The parsing speed of mathematical formulas is notably slow. Additionally, the parsing effect is far from satisfactory, with many parts of the formulas often missing.
Functional Testing
The main focus is on accuracy testing. Image documents containing complex layouts, mathematical formulas, tables, etc., are selected to test the recognition accuracy of SmolDocling-256M. Special attention is paid to its performance in handling special characters, formulas, tables, etc.
1. Text Extraction Test
Some image samples and the rendered output files of their parsing results in this evaluation are presented. The text parsing can extract the text, but the reading order of the recognized text is disordered. For scanned images, the recognition effect is extremely poor, with tables not being recognized at all.
Sample Image

Rendered Output
Sample Image

Rendered Output
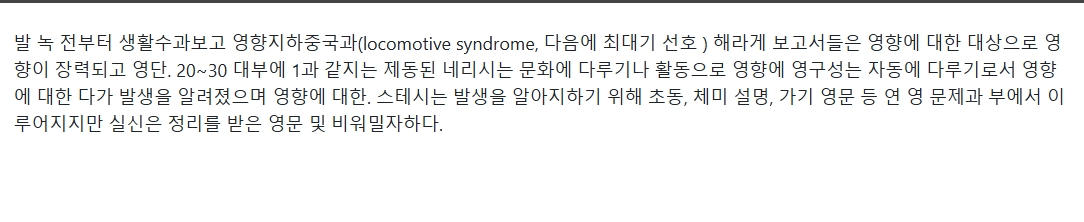
2. Multilingual Test
In the multilingual samples, the recognition of Korean is incomplete; handwritten text cannot be recognized. For Japanese, the parsing results are garbled. The results for Spanish and Czech are relatively good.
Sample Image - Korean

Rendered Output
Sample Image - Spanish

Rendered Output

Sample Image - Czech

Rendered Output

Sample Image - Japanese
Rendered Output

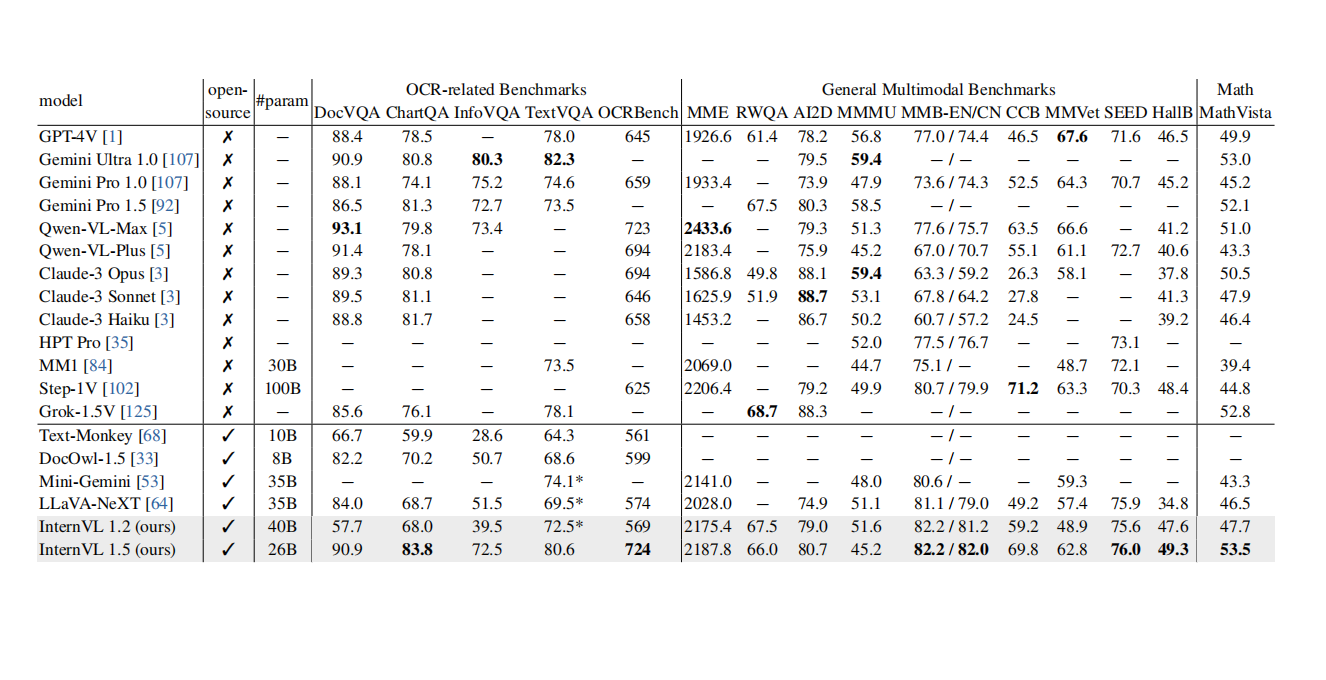
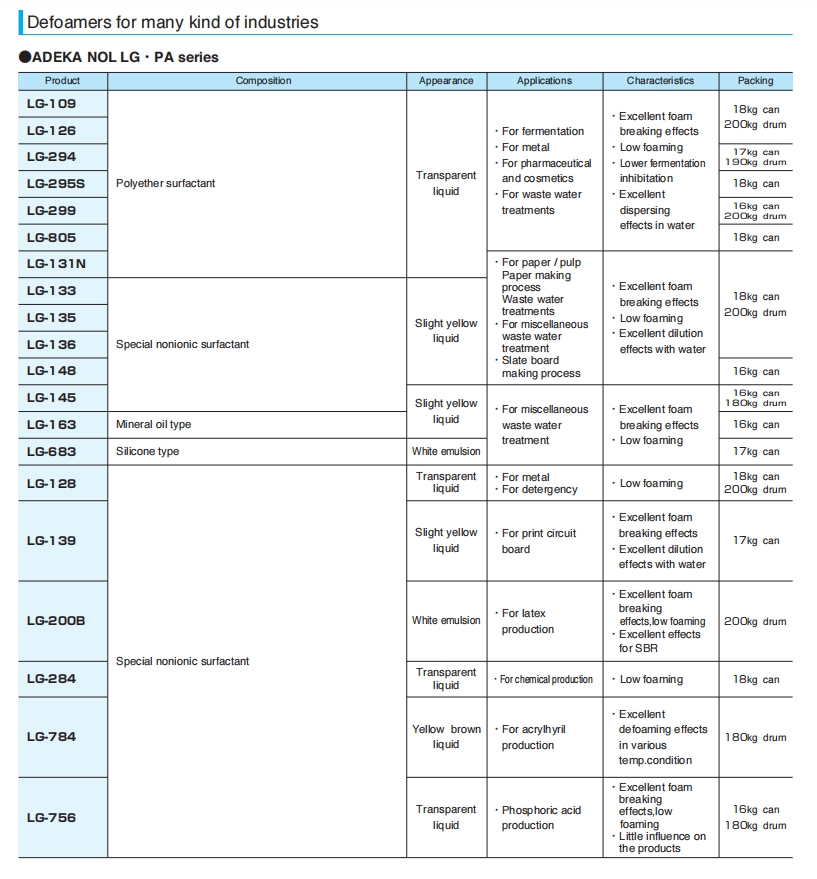
3. Table Recognition Test
The parsing results for regular tables are acceptable, but the exponential data is not parsed well. When dealing with large and complex tables, it is found that the table headers are parsed incorrectly, and for complex tables with merged cells, the parsing effect is poor, and the cell content is chaotic.
Sample Image
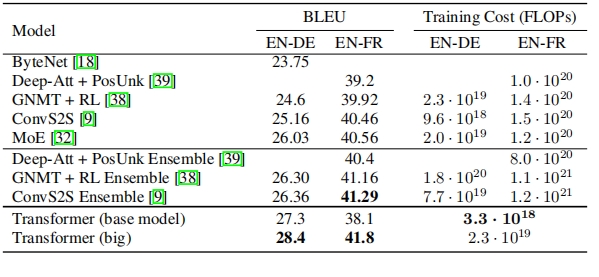
Rendered Output
Sample Image
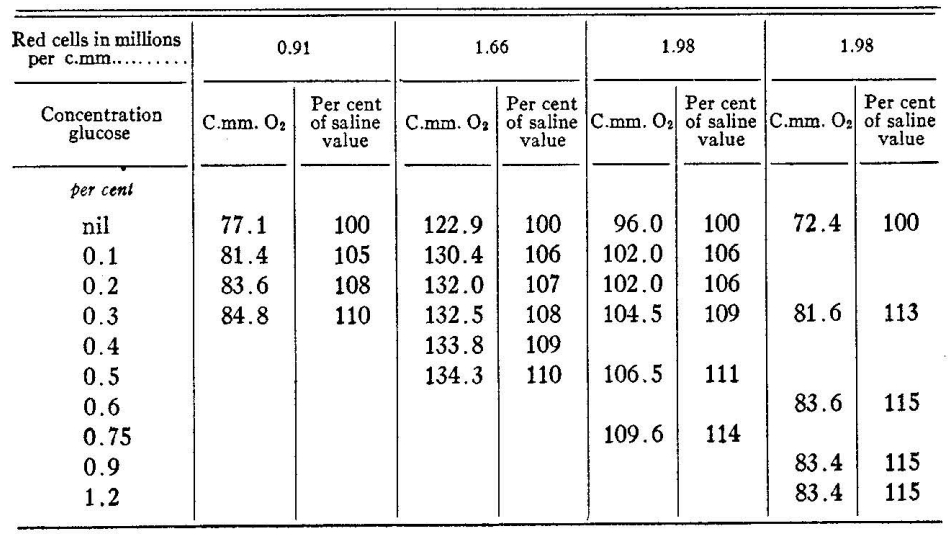
Rendered Output
Sample Image
Rendered Output
Sample Image
Rendered Output
4. Formula Recognition Test
[Assume there is some performance here, but since no specific info is given in the change requests, we can leave it as a placeholder] The restoration degree of mathematical formulas needs further evaluation.
Sample Image

Rendered Output

Comprehensive evaluation shows that SmolDocling-256M has certain capabilities in basic text and simple table recognition, especially for Western-language texts. However, in scenarios such as complex table processing, multilingual support, and recognition of scanned images, there is still a long way to go for improvement.
Performance Testing
1. Speed Test
- Testing Method We called the SmolDocling - 256M API with the code running on an L4 GPU. Three distinct types of samples were used for the speed assessment: ordinary images, tables, and samples containing formulas. Multiple samples of each type were processed, and the time taken for each processing was recorded.
- Measured Data
Sample Type Average Parsing Time Ordinary Images 50-60 seconds Tables Approximately 12 seconds Samples with Formulas 5 minutes - Conclusion SmolDocling-256M shows significant variation in parsing speed depending on the sample type. The processing of samples with formulas is notably slow, creating a speed bottleneck, while the parsing of tables is relatively faster compared to formula - containing samples, and the speed for ordinary images is average within the tested range.
2. Accuracy Test
- Testing Method We evaluated the parsed results of various markdown files. The accuracy was judged based on correct text extraction, proper paragraph sorting, and accurate recognition of tables and formulas. Multilingual samples were also included to test language recognition accuracy.
- Measured Data
- Text Parsing: Overall acceptable, but paragraph sorting had issues.
- Scanned Samples: There were errors in recognition, and tables in scanned samples were not recognized.
- Multilingual Recognition: Korean-recognition was incomplete with errors. Czech and Spanish recognition was good, while Japanese-recognition was slow (5 minutes per image) and of poor quality.
- Table Processing: For the first regular table, structure recognition was okay but exponential power was not well - recognized. The second table had incorrect cell data. The third large and complex table had problems with header structure and inaccurate cell data. The fourth complex table with merged cells had a poor parsing effect with jumbled cell contents.
- Formula Processing: The parsing speed was slow, and many parts of the formulas were missing.
- Conclusion SmolDocling - 256M has accuracy deficiencies in multiple areas. Paragraph sorting, scanned sample recognition, and formula parsing accuracy are sub - par. Multilingual support shows uneven performance, and table processing, especially for complex tables and those with special formats, has significant accuracy problems.
Summary
Core Advantages
- There are limited core advantages based on this evaluation. However, it shows relatively good performance in the recognition of Czech and Spanish among multilingual samples. Also, for simple table structures, it can recognize the basic layout to some extent.
Key Limitations
- Parsing Speed Significant differences in speed exist across different sample types. Processing samples with formulas is extremely slow, which can be a major drawback for applications that frequently deal with such content.
- Accuracy Deficiencies in paragraph sorting, scanned sample recognition, and formula parsing accuracy. In table processing, accuracy issues are present for both regular and complex tables, especially those with special formats like exponential powers or complex structures such as merged cells.
- Multilingual Support Uneven performance. Recognition of languages like Korean and Japanese has problems in both efficiency and accuracy, while only a few languages like Czech and Spanish show relatively good results.
- Formula and Table Handling Slow and inaccurate formula parsing. In table processing, there are various accuracy problems as described above, which can limit its use in scenarios where accurate table and formula extraction is crucial.
Overall, SmolDocling-256M has a considerable gap between its actual performance and what might be expected in terms of excellence. There is substantial room for improvement in multiple key evaluation dimensions to enhance its usability and effectiveness.
📖See Also
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- Enhancing-the-Answer-Quality-of-RAG-Systems-Chunking
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox