Undatas.io Feature Upgrade Series2 : OCR Multilingual Expansion


1. Introduction: The Need for Multilingual Communication
In today’s globalized world, effective communication across languages is more important than ever. Undatas.io recognizes this need and has made significant strides in 2025 with the expansion of its Optical Character Recognition (OCR) capabilities to support an impressive 84 languages. This upgrade is poised to revolutionize how users interact with documents in multiple languages, enhancing accessibility and usability.
2. Key Features of the Multilingual OCR Functionality
The multilingual OCR functionality allows users to accurately recognize and convert text from a wide array of languages, including major ones like Japanese, Chinese, English, French, and Arabic. This feature is particularly beneficial for businesses operating in international markets, researchers working with diverse literature, and individuals managing multilingual documents.
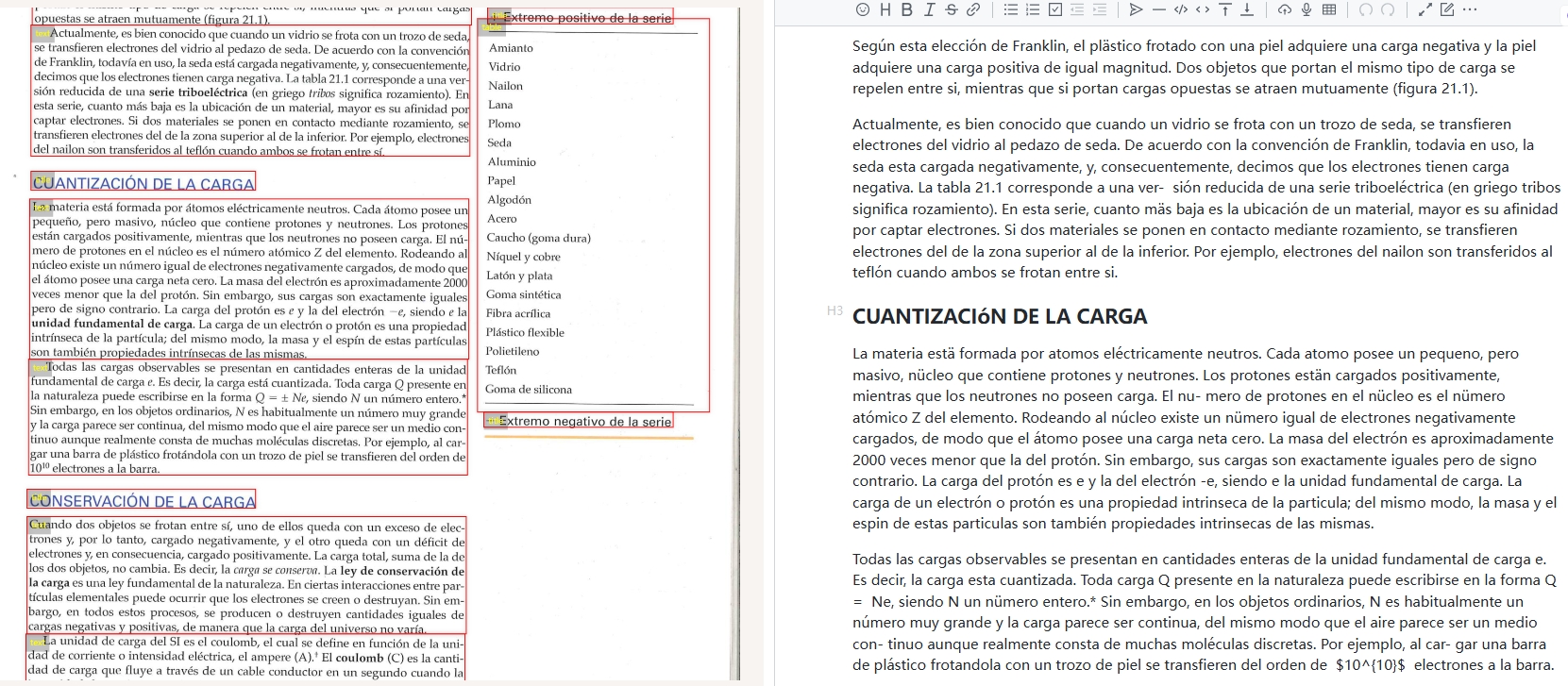
3. Precision and Accuracy in Text Recognition
One of the key advantages of this expansion is the precision with which the OCR technology operates. With advanced machine learning algorithms trained on extensive datasets, users can expect high accuracy in text recognition, even with complex scripts and varying fonts. This ensures that critical information is not lost in translation, allowing for seamless document processing.
4. Breaking Down Language Barriers
Furthermore, the multilingual OCR capability facilitates the extraction of valuable data from contracts, research papers, and other critical documents, breaking down language barriers that often hinder effective communication. Users can now easily convert foreign language documents into structured data, making it accessible for analysis and decision-making.
5. Fostering Inclusivity and Collaboration
The implications of this upgrade extend beyond mere text recognition. By enabling users to work with documents in their native languages, Undatas.io fosters inclusivity and enhances collaboration in diverse teams. This is particularly important in fields like academia and international business, where understanding nuanced content is essential.
6. Sample Output of Undatas.io Parsing
Here is a sample output showcasing the results after parsing documents in various languages with Undatas.io:
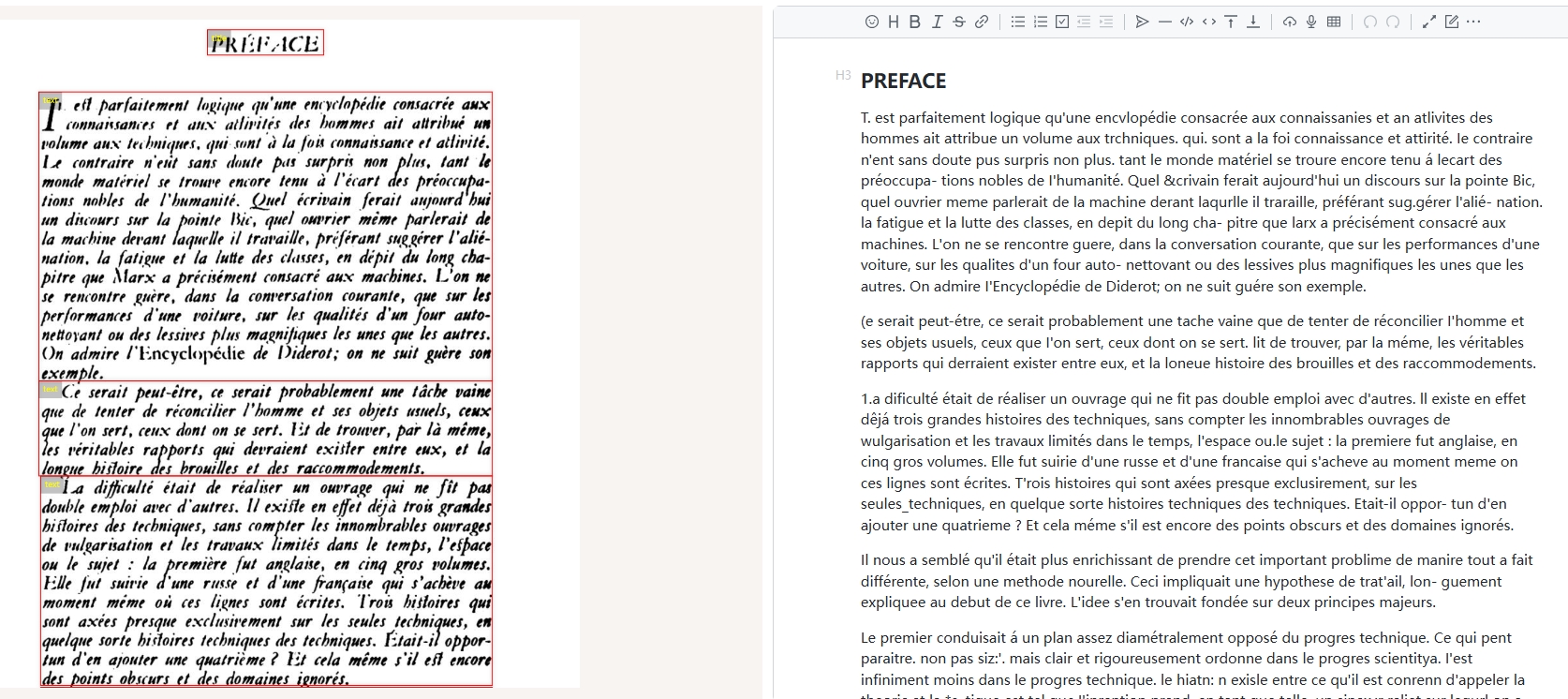
English:

Czech:
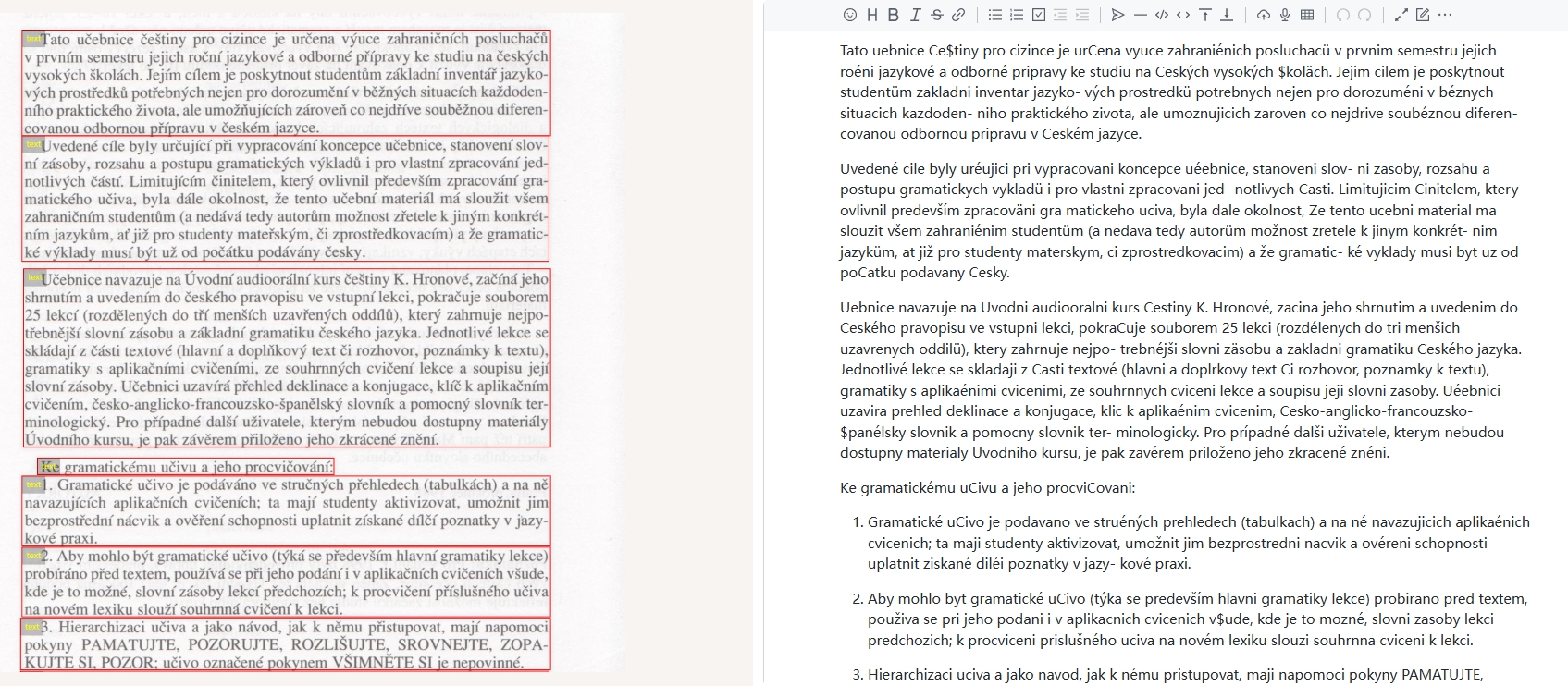
Japanese:
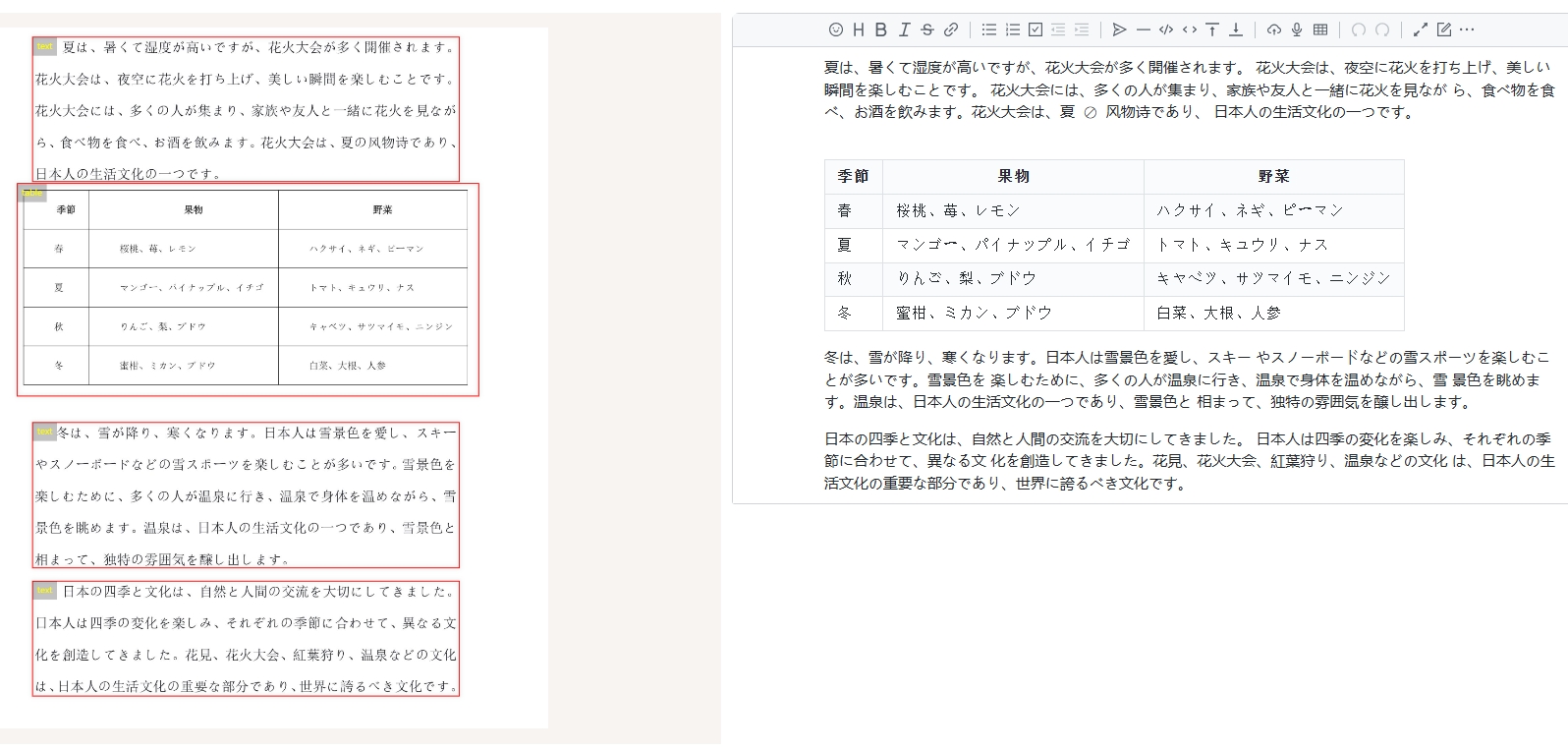
French:
Korean:
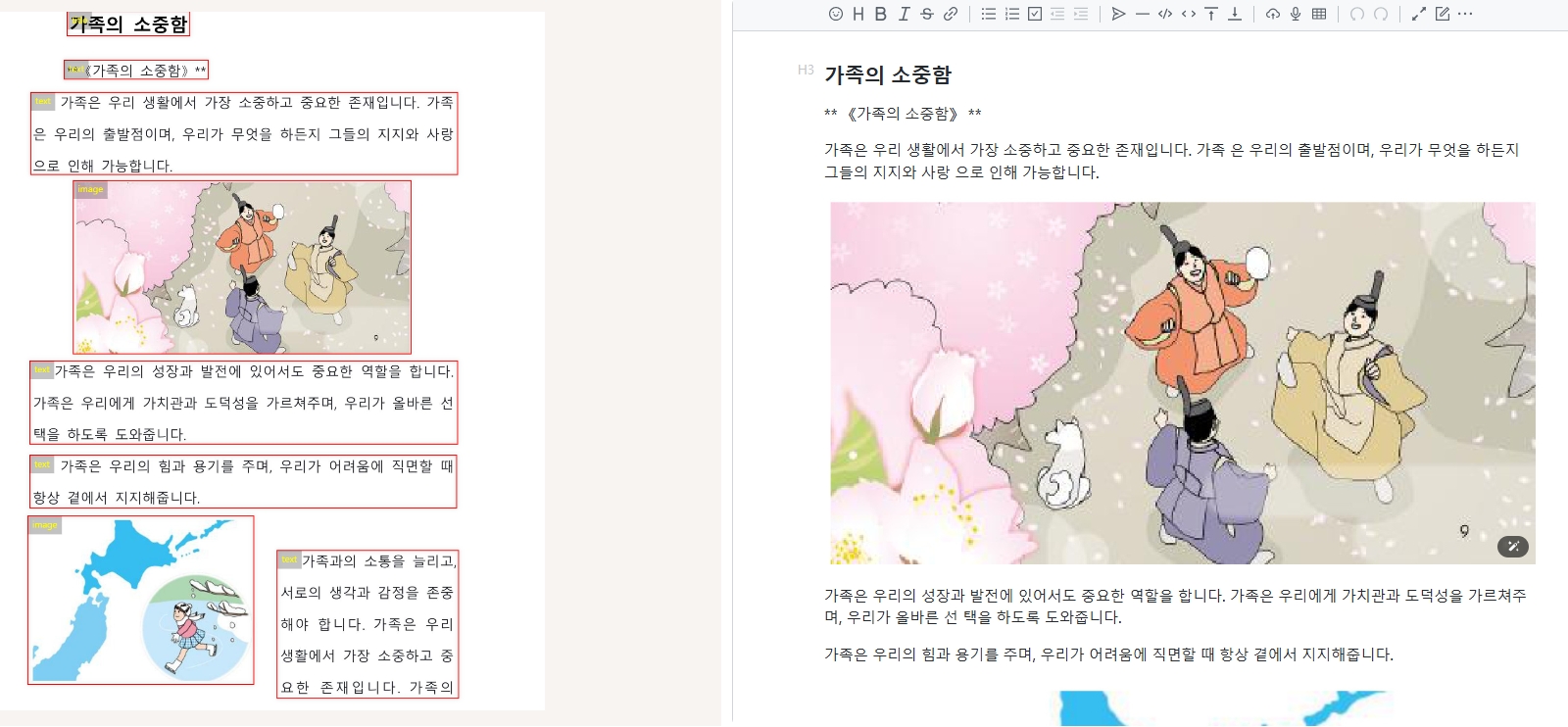
Hindi:
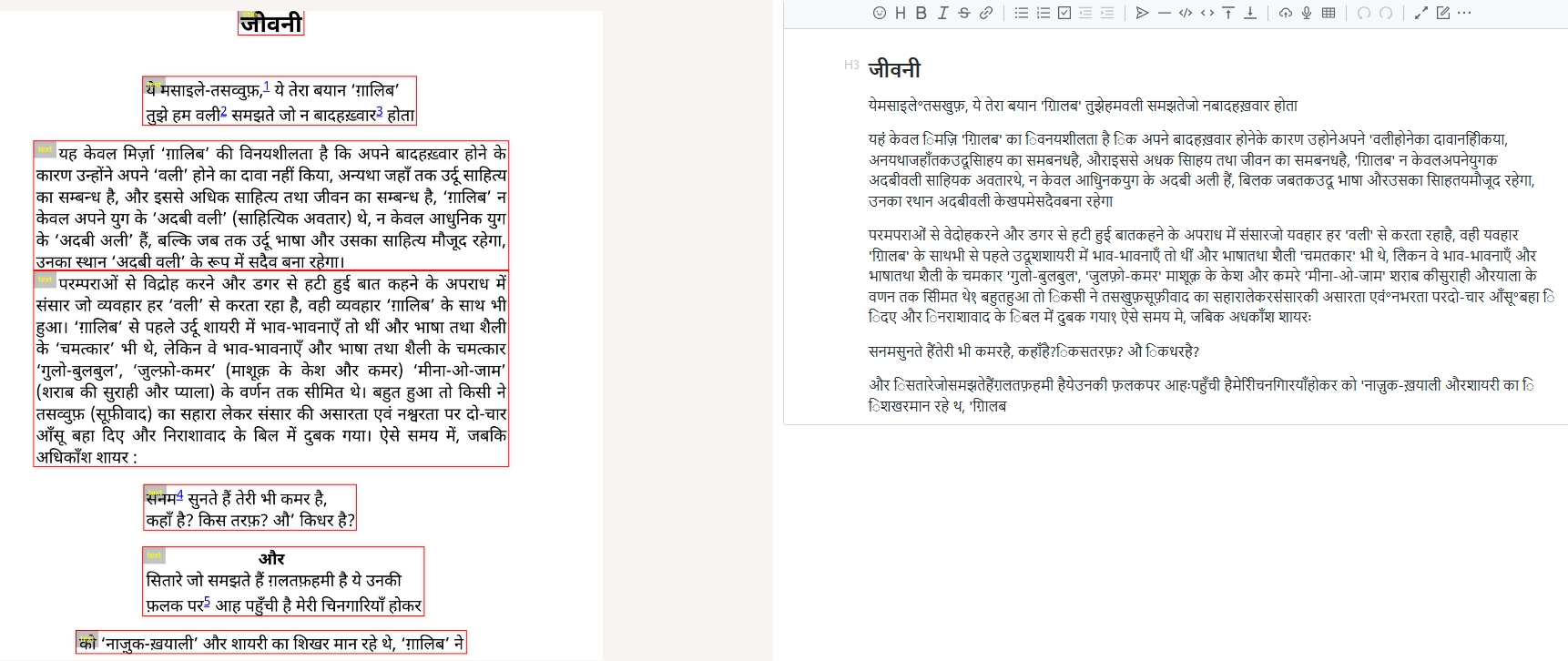
Spanish:
7. Conclusion: Setting a New Benchmark for OCR Technology
As we continue to explore the features of Undatas.io in 2025, it’s clear that the OCR multilingual expansion is a significant step towards making document processing more inclusive and efficient. This upgrade not only meets the demands of a global audience but also sets a new benchmark for OCR technology in the industry. Stay tuned for more insights into the exciting features being introduced this year!
📖See Also
- UndatasIO-2025-New-Upgrades-and-Features
- UndatasIO-Feature-Upgrade-Series1-Layout-Recognition-Enhancements
- Turbocharging-Math-Problem-Solving-with-Undatasio-and-Qwen-max-Model
- The-Key-to-Building-Powerful-RAG-Applications-Mastering-Unstructured-Data
- Process-of-parsing-a-PDF-in-undatasio-platform
- Mastering-RAG-Optimization-The-Ultimate-Guide-to-Unstructured-Document-Parsing
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox