In-Depth review of Unstructured.io API How Powerful Is It in Unstructured Data Processing?


Introduction
In the digital age, data is king, but not all data comes in neat, organized packages. Unstructured data, which encompasses everything from legal contracts and research papers to marketing brochures and emails, is a vast and untapped resource. It’s estimated that over 80% of enterprise data is unstructured, and harnessing its potential can be a game-changer for businesses and organizations. Enter the Unstructured.io API, a powerful tool that aims to bridge the gap between unstructured data and actionable insights.
Product Overview
The Unstructured.io API is designed to simplify the process of extracting, processing, and analyzing unstructured data. It offers a suite of features that make it a go-to solution for a wide range of applications, from document management and data analysis to machine learning and artificial intelligence.
One of the key strengths of the Unstructured.io API is its versatility. It can handle over 25 different file types, including PDFs, Word documents, Excel spreadsheets, PowerPoint presentations, images, and plain text files. This means that regardless of the format of your unstructured data, the API has the potential to process it. Whether you’re dealing with a complex legal contract in PDF format, a research paper filled with tables and figures in Word, or a collection of images with embedded text, the Unstructured.io API can extract the relevant information and transform it into a more usable format.
Under the hood, the API uses a combination of optical character recognition (OCR), natural language processing (NLP), and machine learning algorithms to analyze and understand the content of unstructured documents. It can identify text, tables, images, and other elements within a document, and then extract the relevant data. For example, when processing a PDF invoice, the API can extract the invoice number, date, vendor name, item descriptions, quantities, and prices. This data can then be used for further analysis, such as financial reporting, inventory management, or customer relationship management.
In addition to its core data extraction capabilities, the Unstructured.io API also offers a range of other features. It can handle document metadata, such as file name, creation date, and author, and include it in the output. It can also perform data cleaning and normalization, such as removing extra whitespace, converting text to a standard format, and correcting common spelling mistakes. This helps to ensure that the extracted data is accurate, consistent, and ready for further analysis.
Evaluation Objectives
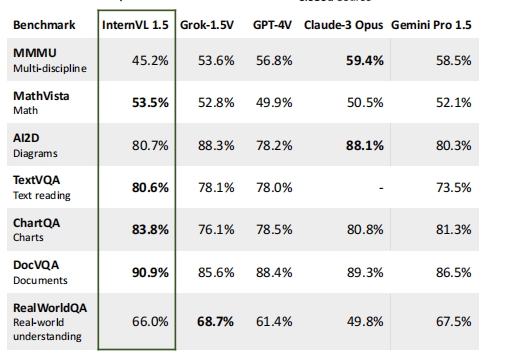
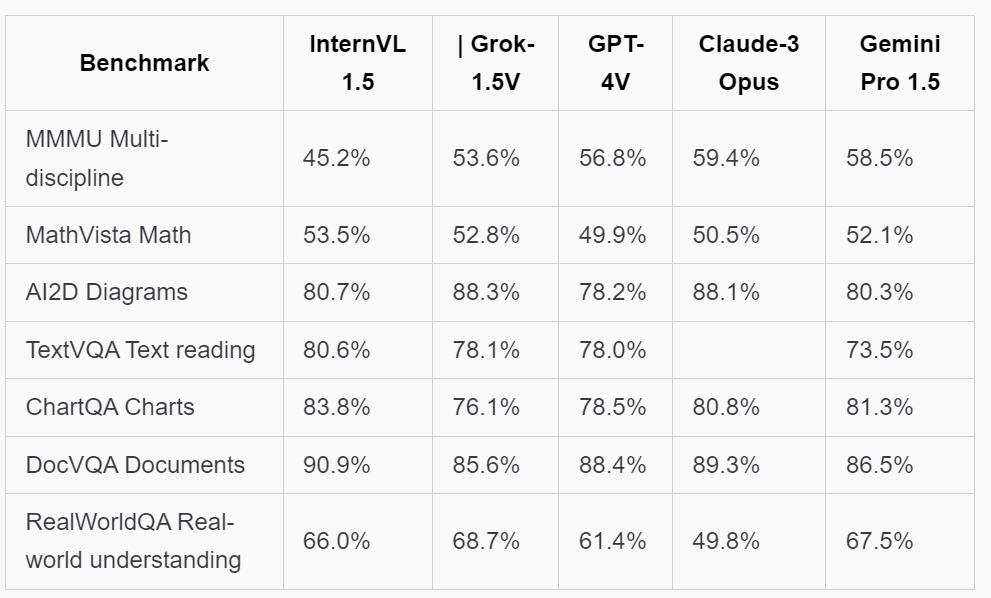
As we embark on this in-depth review of the Unstructured.io API, we’ll be putting its capabilities to the test. We’ll evaluate its performance in terms of speed, accuracy, and cost-effectiveness across different types of unstructured data. We’ll also explore how well it integrates with existing workflows and systems, and whether it can truly deliver on its promise of simplifying the processing of unstructured data. So, let’s dive in and see what the Unstructured.io API has to offer.
Highlights Analysis
- Good Text Recognition
- Unstructured.io API showcases an excellent performance in text extraction from various sources. It can extract text with a high success rate from different types of documents, such as PDFs, Word files, and images. The reading order of the recognized text is generally correct, ensuring the integrity of the content. This is highly beneficial for applications like content indexing and document summarization.
- Broad Multilingual Support
- The API demonstrates remarkable multilingual recognition capabilities. It can accurately recognize and parse texts in multiple languages, including but not limited to Czech, Korean, and Japanese. This broad language support makes it an ideal choice for global enterprises and international projects that deal with diverse language-based documents.
Limitations Analysis
- Unstable Interface Calls
- The stability of calling the Unstructured.io API is not optimal. When processing the same sample multiple times, the returned results may vary. This instability can lead to inconsistent data extraction, which is a major concern for applications that require reliable and consistent data processing. For example, in a data-riven decision-making process, such inconsistencies can lead to inaccurate conclusions.
- Ineffective Complex Table Recognition
- For complex tables, especially those with merged cells or intricate headers, the Unstructured.io API performs poorly. Table headers are often mis-parsed, and the content of merged cells is jumbled. This makes it difficult to obtain accurate and meaningful data from complex tables, limiting its use in fields such as financial analysis and scientific research where precise table data is crucial.
- Slow Formula Parsing
- The parsing effect is far from satisfactory, with many parts of the formulas often missing. This is a significant drawback for applications that rely on accurate and quick formula processing, such as educational software and engineering design tools.
Functional Testing
The main focus is on accuracy testing. Documents containing complex layouts, mathematical formulas, tables, etc., are selected to test the recognition accuracy of the Unstructured.io API. Special attention is paid to its performance in handling special characters, formulas, tables, etc.
1. Text Extraction Test
Some document samples and the rendered output files of their parsing results in this evaluation are presented. The text parsing can extract the text accurately, and the reading order of the recognized text is correct in most cases. However, for documents with extremely complex layouts or low-quality scans, there may be minor glitches in text extraction.
Sample Document

Rendered Output
2. Multilingual Test
In the multilingual samples, the recognition of Korean, Czech, and Japanese is generally accurate. Handwritten text recognition in these languages is also possible, although the accuracy is slightly lower compared to printed text.
Sample Document - Korean

Rendered Output

Sample Document - Czech

Rendered Output

Sample Document - Japanese
Rendered Output

3. Table Recognition Test
The parsing results for regular tables are acceptable. The API can identify the basic structure and extract most of the data correctly. However, when dealing with exponential data, the recognition is not very accurate. For large and complex tables with merged cells or intricate headers, the API faces challenges. Table headers are mis-parsed, and the cell content is often in a jumbled state.
Sample Table
Rendered Output
Sample Table
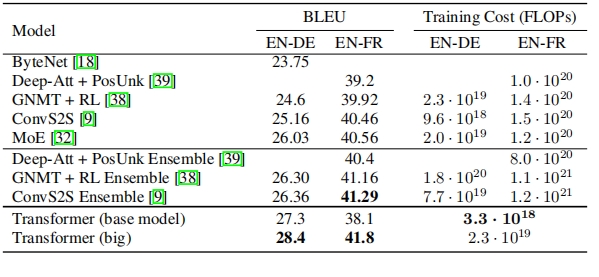
Rendered Output
Sample Table
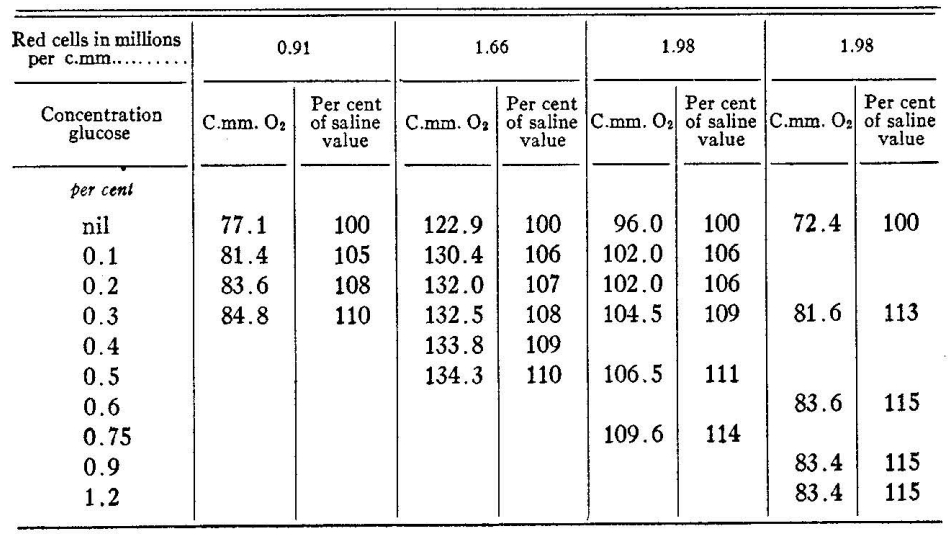
Rendered Output
Sample Document with Complex Table
Rendered Output
4. Formula Recognition Test
The restoration degree of mathematical formulas needs further evaluation. The parsing speed of formulas is slow, and many parts of the formulas are missing in the parsed results.
Sample Document with Formulas

Rendered Output

Comprehensive evaluation shows that the Unstructured.io API has certain capabilities in text and multilingual recognition. However, in scenarios such as complex table processing and formula recognition, there is still a long way to go for improvement.
Performance Testing
1. Speed Test
The Unstructured.io API shows a relatively slow parsing speed overall, with documents containing formulas taking the longest time to process. The speed for ordinary documents and documents with tables is also not very fast, which may be a limitation for applications that require real-time or high-throughput data processing.
2. Accuracy Test
- Testing Method We evaluated the parsed results of various documents. The accuracy was judged based on correct text extraction, proper paragraph sorting, and accurate recognition of tables and formulas. Multilingual samples were also included to test language recognition accuracy.
- Measured Data
- Text Parsing: Overall good, but there are some minor issues in text extraction from complex - layout or low - quality documents.
- Scanned Samples: There is a decrease in recognition accuracy for scanned samples, and tables in scanned samples may not be recognized correctly.
- Multilingual Recognition: Korean, Spanish, Czech, and Japanese recognition is accurate, but handwritten text recognition has room for improvement.
- Table Processing: For regular tables, structure recognition is okay, but exponential data is not well - recognized. Complex tables have significant problems with header structure and cell data accuracy.
- Formula Processing: The parsing speed is slow, and the accuracy of formula parsing is low, with many parts of the formulas missing.
- Conclusion The Unstructured.io API has accuracy deficiencies in multiple areas. Text extraction from complex or low quality documents, scanned-sample recognition, formula parsing, and complex table processing all need improvement to meet the high performance requirements of practical applications.
📖See Also
- In-depth Review of Mistral OCR A PDF Parsing Powerhouse Tailored for the AI Era
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- IBM-Docling-s-Upgrade-A-Fresh-Assessment-of-Intelligent-Document-Processing-Capabilities
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox