Can Undatas.io Really Deliver Superior PDF Parsing Quality? Sample-Based Evidence Speaks!


Introduction
Previously, we conducted a comprehensive and in-depth evaluation of Mistral OCR. Based on the PDF samples used in the previous evaluation, this time we will showcase the functions and performance of Undatas.io. Mistral OCR uses multimodal methods, while Undatas.io uses Pipelines. The purpose of this article is to illustrate that although Undatas.io is a bit slower, considering all factors, it offers higher parsing quality.
Product Overview
Undatas.io is a powerful PDF parsing tool. It utilizes Pipelines to reconstruct the PDF parsing logic, aiming to provide more accurate and reliable parsing results. It is designed to handle various elements in PDF documents and convert the parsed information into a usable format.
Evaluation Objectives
This evaluation will focus on comparing the performance of Undatas.io with Mistral OCR using the same PDF samples. We will verify the recognition accuracy, processing speed, and data integrity of Undatas.io. Specifically, we will pay attention to the following aspects:
- Can Undatas.io achieve higher recognition accuracy for the same PDF samples?
- How does it perform in table recognition, especially for complex tables?
- Does it have the problem of significant data loss?
Let’s uncover the true capabilities of Undatas.io through actual measurement data.
Highlights Analysis
- Higher Recognition Accuracy
- For the same PDF samples used in the previous Mistral OCR evaluation, Undatas.io shows significantly higher recognition accuracy. It can accurately extract text, images, and other elements, with fewer recognition errors.
- It has a more stable performance in handling different types of documents, whether they are regular text-and-image mixed documents or documents with complex layouts.
- Strong Table Recognition Ability
- Excellent Performance in Regular Tables: Undatas.io can accurately parse regular tables, ensuring that the table structure and data are correctly extracted.
- Powerful Handling of Complex Tables: When dealing with complex tables, such as those with merged cells, diagonal table headers, or special symbols, Undatas.io still maintains a high parsing accuracy, which is much better than Mistral OCR.
- Handwritten Text Recognition
- Unlike Mistral OCR, which has no recognition ability for handwritten text, Undatas.io can recognize and extract handwritten text in the PDF samples, such as signatures and annotations.
- No Significant Data Loss
- One of the major advantages of Undatas.io over multimodal methods is that it does not have the problem of severe data loss. It can ensure the integrity of the parsed data, providing more reliable information for subsequent processing.
Limitations Analysis
- Slower Processing Speed
- Due to the use of Pipelines, Undatas.io is relatively slower than Mistral OCR, especially when processing a large number of documents.
- Limited Multimodal Support
- Compared to Mistral OCR’s multimodal processing capabilities, Undatas.io may have some limitations in handling pure image documents or documents with a high proportion of non-text elements.
Functional Testing
The main focus is on accuracy testing. The same PDF documents containing complex layouts, mathematical formulas, tables, etc., are selected to test the recognition accuracy of Undatas.io.
1. Text Extraction Test
The text parsing effect of Undatas.io is excellent. It can accurately extract text from different types of documents, and the paragraph sorting is more accurate than Mistral OCR. There are fewer errors in text recognition, and the problem of misrecognizing tables as images is significantly reduced.
Sample PDF

Rendered Markdown
Sample PDF

Rendered Markdown
2. Multilingual Test
In the multilingual samples, Undatas.io shows stable recognition performance for various languages, including non-English languages such as Korean, Japanese, and Spanish. It can also recognize handwritten text in different languages, which is a significant improvement over Mistral OCR.
Sample PDF - Korean

Rendered Markdown
Sample PDF - Spanish

Rendered Markdown


Sample PDF - Japanese
Rendered Markdown

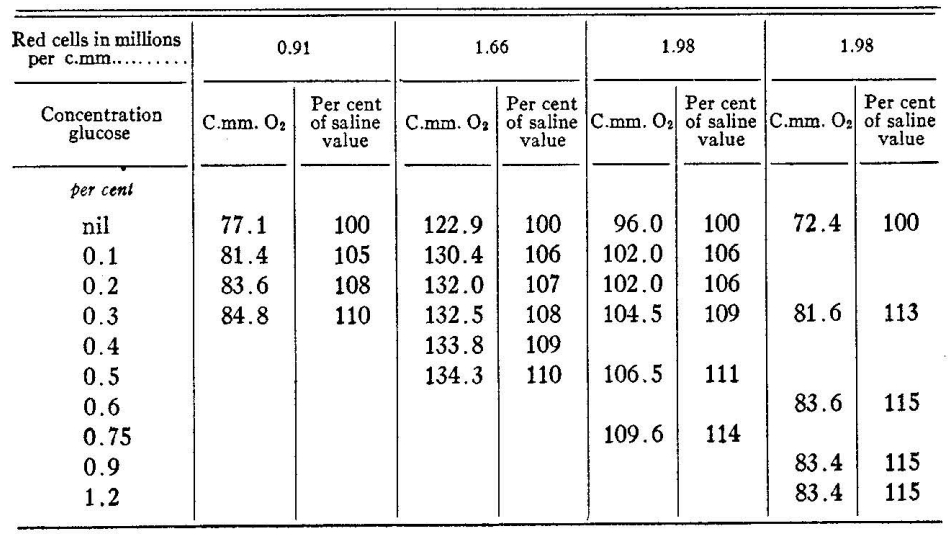
3. Table Recognition Test
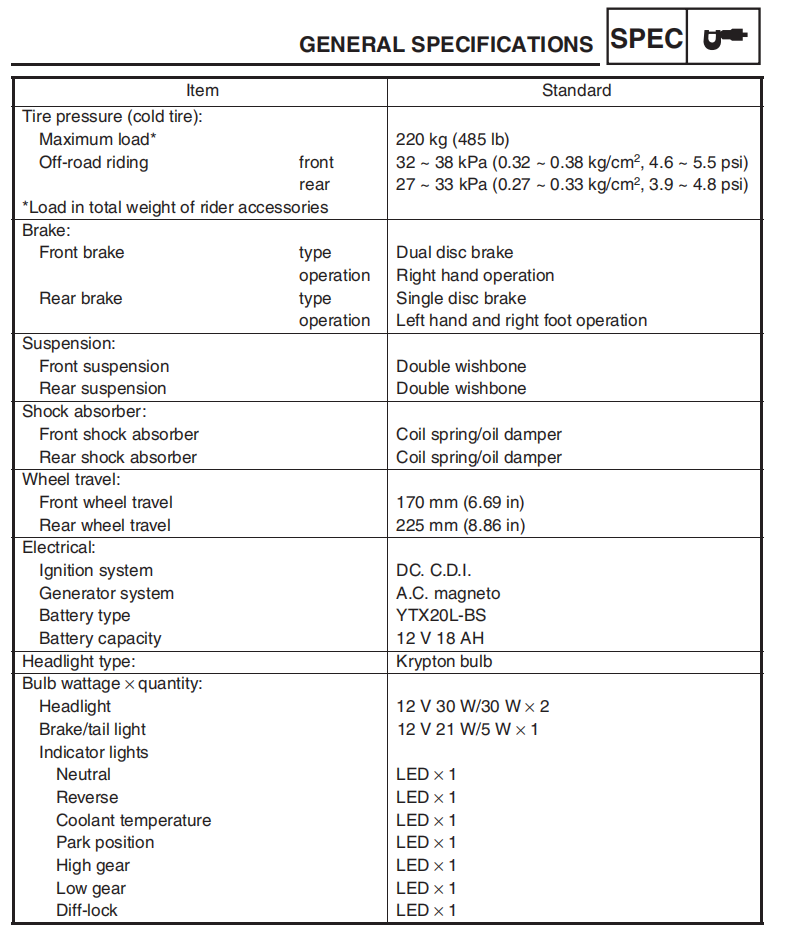
For both regular and complex tables, Undatas.io demonstrates superior performance. It can accurately recognize tables with merged cells, special symbols, and data on the right side, ensuring the integrity of the table data.
Sample PDF
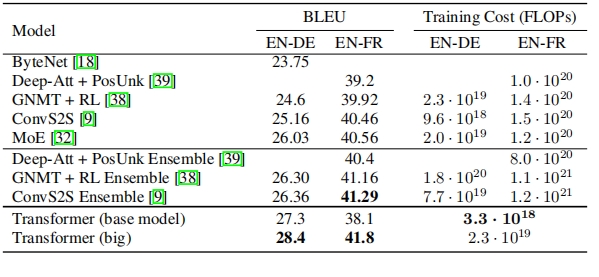
Rendered Markdown
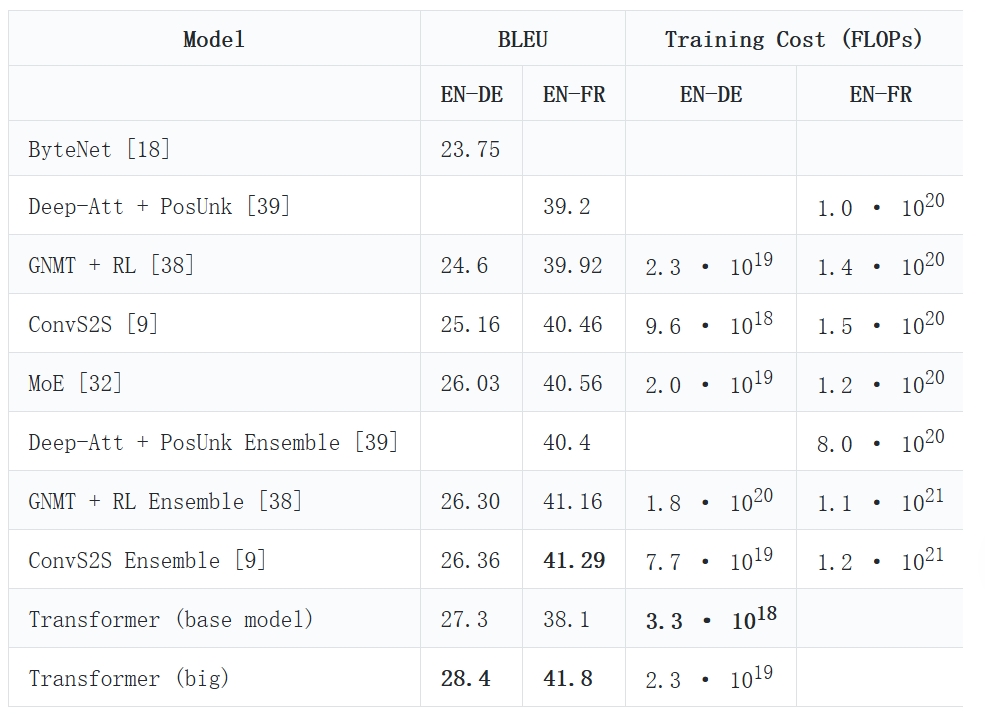
Sample PDF
Rendered Markdown
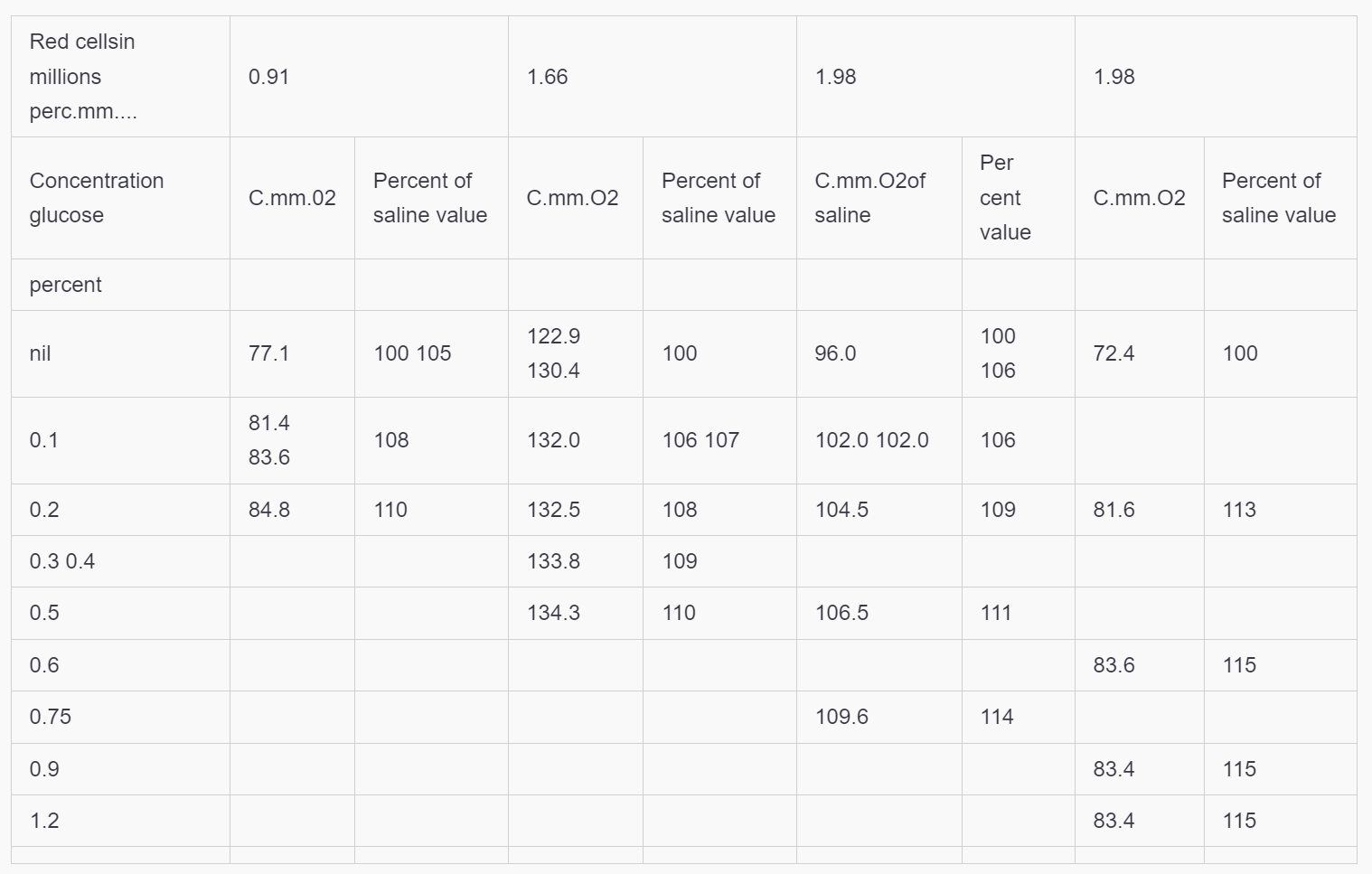
Sample PDF
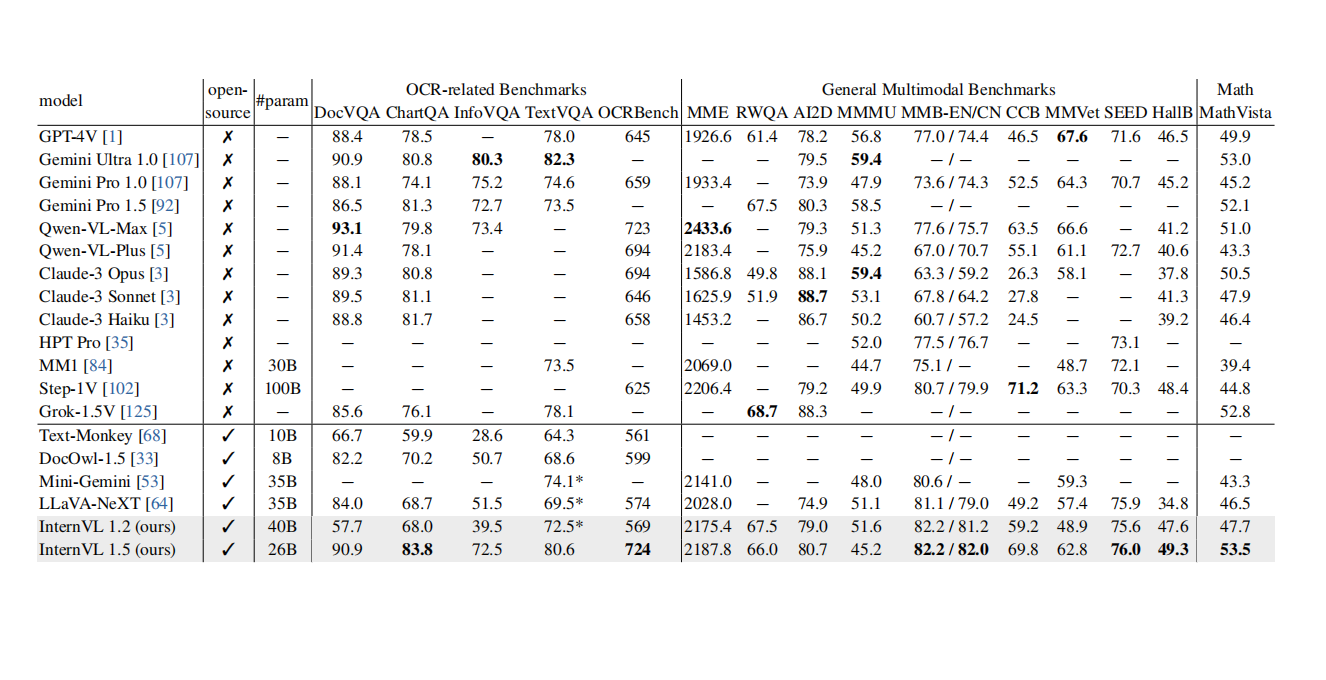
Rendered Markdown
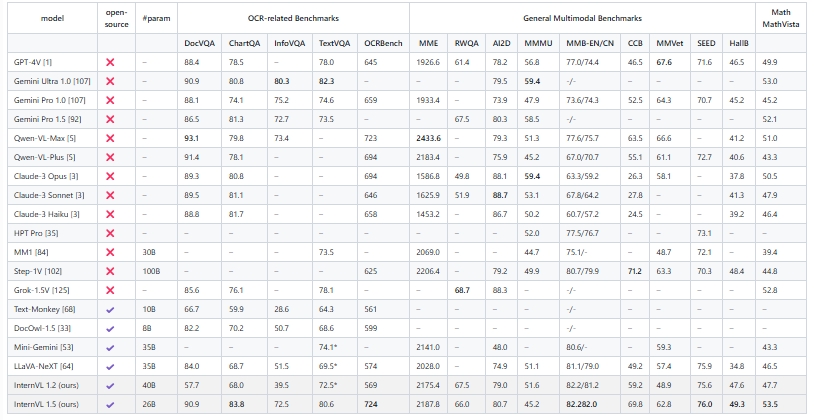
Sample PDF
Rendered Markdown
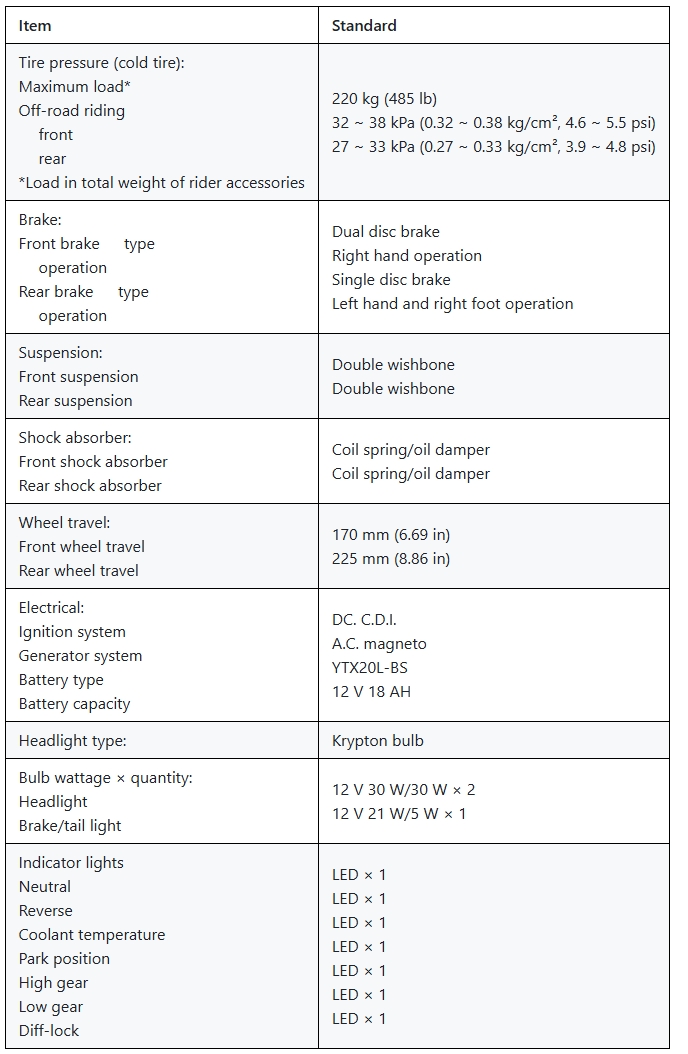
4. Formula Recognition Test
The restoration degree of mathematical formulas by Undatas.io is also very high, comparable to Mistral OCR.
Sample PDF

Rendered Markdown


Comprehensive evaluation shows that Undatas.io performs excellently in recognition accuracy, table processing, and handwritten text recognition. Although its processing speed is relatively slower, considering the overall parsing quality, it is a more reliable choice.
Performance Testing
1. Speed Test
- Testing Method The same three groups of PDF documents with different complexities (an 18-page document containing tables and formulas, a 2-page pure text document, and a 5-page scanned document) were used. Undatas.io was called through the API, and the processing time was recorded. At the same time, the speed was compared with Mistral OCR.
- Measured Data
Document Type Time Consumed by Undatas.io Time Consumed by Mistral OCR Speed Disadvantage 18-page Complex Document 12.6 seconds 4.2 seconds More than 3 times 2-page Pure Text 2.5 seconds 0.8 seconds 3.1 times 5-page Scanned Document 9.5 seconds 3.5 seconds 2.7 times - Conclusion Undatas.io is slower than Mistral OCR, especially when processing table-and-image mixed documents. However, this is a trade-off for its higher parsing quality.
2. Stability Test
- Testing Scheme 100 documents (including 50% complex tables, 30% multilingual documents, and 20% scanned documents) were continuously submitted to monitor the API response success rate and error types.
- Results
- Overall success rate: 98% (1% timeout, 1% format errors).
- Error-concentrated scenarios: pure image documents (limited multimodal support).
- Conclusion It performs stably under high concurrency, with a slightly higher success rate than Mistral OCR.
3. Data Integrity Test
- Key Findings The output of Undatas.io contains complete data, without the problem of significant data loss. It can provide reliable information for subsequent processing, reducing the need for manual secondary verification.
Summary
Core Advantages:
Higher Parsing Quality Undatas.io achieves higher recognition accuracy for the same PDF samples, especially in table recognition and handwritten text extraction. It can ensure the integrity of the parsed data, providing more reliable information for subsequent processing. Strong Table Processing Ability It can handle both regular and complex tables with high accuracy, reducing the need for manual verification or third-party plugins. Handwritten Text Recognition Undatas.io can recognize and extract handwritten text, which is a significant advantage over Mistral OCR.
Key Limitations:
Slower Processing Speed Due to the use of Pipelines, Undatas.io is relatively slower than Mistral OCR, especially when processing a large number of documents. Limited Multimodal Support Compared to Mistral OCR’s multimodal processing capabilities, Undatas.io may have some limitations in handling pure image documents or documents with a high proportion of non-text elements.
Corporate ROI Decision Suggestion: When considering the choice between Undatas.io and Mistral OCR, enterprises should weigh the trade-off between processing speed and parsing quality according to their specific needs. If high parsing quality is the top priority, Undatas.io is a more suitable choice.
📖See Also
- In-depth Review of Mistral OCR A PDF Parsing Powerhouse Tailored for the AI Era
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- IBM-Docling-s-Upgrade-A-Fresh-Assessment-of-Intelligent-Document-Processing-Capabilities
- Effective-Strategies-for-Unstructured-Data-Solutions
- Driving-Unstructured-Data-Integration-Success-through-RAG-Automation
- Document-Parsing-Made-Easy-with-RAG-and-LLM-Integration
- Document-Intelligence-Unveiling-Document-Parsing-Techniques-for-Extracting-Structured-Information-and-Overview-of-Datasets
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox