The Unseen Grid: A Comprehensive Analysis of Borderless Table Recognition Technology


Of course. As the Content Lead for undatasio, I will rework the provided comprehensive analysis into a compelling and concise Medium blog post. The goal is to retain the core technical narrative and key details while making the content more accessible, engaging, and suitable for a tech-savvy audience.
Decoding the Unseen Grid: The AI Revolution in Borderless Table Recognition
From messy documents to structured data, a look inside the deep learning magic that makes it possible.
In our digital world, we’re drowning in data. But here’s the paradox: a vast amount of the world’s most valuable structured information remains trapped, locked away in unstructured documents like PDFs and images. The key to unlocking it often lies in a task that is deceptively complex: table recognition.
While Optical Character Recognition (OCR) has largely solved the challenge of reading text from an image, identifying tables—especially “borderless” ones without clear lines—is a different beast entirely. It’s not just about reading; it’s about understanding an unseen grid defined by space, alignment, and context.
At undatasio, we tackle this challenge daily. Today, we’re taking you on a deep dive into the technology that powers this magic, from early, clumsy attempts to the sophisticated AI models that are revolutionizing document intelligence.
Why Are Borderless Tables So Hard?
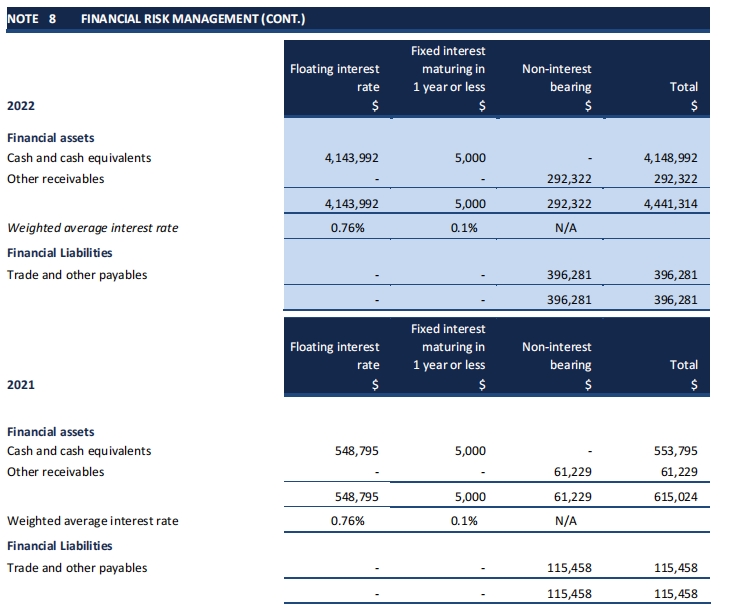 A bordered table is a computer’s best friend. Algorithms can use simple image processing to find the horizontal and vertical lines, easily reconstructing the grid like a puzzle.
A bordered table is a computer’s best friend. Algorithms can use simple image processing to find the horizontal and vertical lines, easily reconstructing the grid like a puzzle.
But a borderless table has none of these explicit cues. Its structure is implied entirely by whitespace, alignment, and the logical grouping of content. The machine has to infer structure from the absence of things (gaps) and the subtle relationships between things (text alignment).
This introduces massive ambiguity:
- Is a multi-column list a table?
- Could a block of justified text be mistaken for a single-column table?
Early solutions relied on heuristic rules, where engineers tried to code human intuition. They wrote rules like “look for vertical stacks of whitespace” or “calculate an alignment score for text blocks.” These systems were incredibly brittle. A slight skew in a scanned document, a merged cell, or text wrapping to a new line would cause them to fail spectacularly. The number of rules needed to cover every real-world variation was simply unmanageable.
The field was stuck. A new approach was needed.
The Evolution: From Brute Force to Brain Power
Deep learning changed the game. Instead of telling the machine how to find a table with rigid rules, we could show it thousands of examples and let it learn the underlying patterns for itself.
-
Convolutional Neural Networks (CNNs): The Visual Pattern Masters
The first wave of AI models, like the influential CascadeTabNet, adapted architectures from mainstream computer vision. They treated table recognition as an object detection task: first, draw a box around the entire table (detection), then identify the rows and columns inside (segmentation). CNNs are brilliant at learning local visual patterns and are robust against the noise and distortions common in scanned documents. -
The Transformer Revolution: Understanding the Bigger Picture
While CNNs are great, they have a form of “tunnel vision,” focusing on local features. The meaning of a cell, however, depends on its alignment with every other cell in its row and column. The Transformer architecture, with its “self-attention mechanism,” solved this perfectly. It can weigh the importance of every part of an image simultaneously, allowing it to capture the global context that defines a table’s grid. -
Models like the Table Transformer (based on DETR) treat table recognition as a “set prediction” problem, directly outputting all structural components (rows, columns, headers) in one pass, dramatically simplifying the pipeline.
-
Graph Neural Networks (GNNs): Seeing Tables as a Network
An even more powerful and abstract approach is to view a document not as pixels, but as a graph. Each word or text block is a node, and the spatial relationships between them (e.g., “is below,” “is aligned with”) are the edges. GNNs are designed to reason over these relationships, learning to identify clusters of nodes that form a grid-like pattern. This method holds immense promise for tackling highly complex and nested table structures.
Let’s Get Practical: Extracting a Financial Table with Python
Enough theory. Let’s see this in action. We’ll use the powerful Table Transformer from the Hugging Face hub to extract a borderless table from a real-world financial statement image.
Step 1: Setup and Installation
First, ensure you have the necessary libraries and Google’s Tesseract OCR engine installed.

# Install dependencies
!pip install -q transformers timm pytesseract pandas Pillow
!sudo apt install tesseract-ocr -y
import torch
from PIL import Image
import pytesseract
import pandas as pd
from transformers import DetrFeatureExtractor, TableTransformerForObjectDetection
# Load your image (ensure you have an image file named 'financial_statement_table.png')
# For this example, you can use this image: https://ustrader-73014.oss-us-east-1.aliyuncs.com/landingpage_video/pic-8/w2.png
image_path = 'financial_statement_table.png'
image = Image.open(image_path).convert("RGB")
Step 2: Recognize Table Structure with the Model
We’ll use a pre-trained model to detect the rows and columns in the image.
# Load model from Hugging Face
feature_extractor = DetrFeatureExtractor()
model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-structure-recognition")
# Prepare image for model and perform inference
encoding = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(** encoding)
# Post-process to get bounding boxes
width, height = image.size
results = feature_extractor.post_process_object_detection(outputs, threshold=0.7, target_sizes=[(height, width)])[0]
# Separate the detected boxes by their labels
boxes = results['boxes'].tolist()
labels = results['labels'].tolist()
rows = [box for box, label in zip(boxes, labels) if model.config.id2label[label] == 'table row']
cols = [box for box, label in zip(boxes, labels) if model.config.id2label[label] == 'table column']
Step 3: Reconstruct Cells and Perform OCR
The model gives us rows and columns, not individual cells. We need to calculate their intersections and then run OCR on each resulting cell area.
def get_cell_coordinates(rows, cols):
"""Calculates cell bounding boxes from row and column boxes."""
cells = []
rows.sort(key=lambda r: r[1])
cols.sort(key=lambda c: c[0])
for row_box in rows:
row_cells = []
for col_box in cols:
cell_box = [col_box[0], row_box[1], col_box[2], row_box[3]]
row_cells.append(cell_box)
cells.append(row_cells)
return cells
cell_grid = get_cell_coordinates(rows, cols)
# Perform OCR on each reconstructed cell
table_data = []
for row_of_cells in cell_grid:
row_text = []
for cell_box in row_of_cells:
cell_image = image.crop(cell_box)
text = pytesseract.image_to_string(cell_image, config='--psm 6').strip()
row_text.append(text)
table_data.append(row_text)
Step 4: Clean and Display the Data
Finally, we assemble the raw text into a clean Pandas DataFrame.
# Convert to DataFrame and perform basic cleaning
df = pd.DataFrame(table_data)
if not df.empty:
df.columns = df.iloc[0]
df = df[1:].reset_index(drop=True)
df = df.applymap(lambda x: str(x).replace('\n', ' ').strip() if x else x)
df.dropna(how='all', axis=0, inplace=True)
df.dropna(how='all', axis=1, inplace=True)
print("Extracted and Cleaned Table Data:")
print(df)
# Save to a CSV file
df.to_csv("extracted_financial_data.csv", index=False)
This complete pipeline shows that a production-ready solution is a composite system: a sophisticated deep learning model does the heavy lifting for structure recognition, but crucial pre- and post-processing logic turns the raw output into clean, usable data.
The Final Frontier: From Extraction to Understanding
The journey doesn’t end here. The toughest challenges remain: real-world documents are filled with merged cells, multi-line text, and even nested tables. Modern architectures are tackling this with “split-and-merge” paradigms that can intelligently reconstruct these complex layouts.
But the true future lies beyond structure, in semantic comprehension. This is where Large Language Models (LLMs) enter the stage.
The emerging workflow looks like this:
- Extract: A specialized model like Table Transformer accurately extracts a table into a structured format like Markdown or JSON.
- Understand: This structured text is fed into an LLM. A user can then ask questions in natural language, like, “What was the total revenue in the fourth quarter?” and the LLM can parse the table data to find the answer.
The long-term vision is for true Vision-Language Models (VLMs) that can reason directly on the document image, seamlessly connecting text in a paragraph to the data in a table, understanding context just like a human.
Conclusion
Borderless table recognition has evolved from a niche, rule-based craft into a science driven by data, advanced architectures, and massive compute. This technology is actively dissolving the boundary between static documents and dynamic databases, turning trillions of pages of dormant information into queryable, actionable knowledge.
For any organization looking to compete in a data-driven world, mastering this technology is no longer a luxury—it’s the key to unlocking the vast, hidden value within your documents.
📖See Also
- In-depth Review of Mistral OCR A PDF Parsing Powerhouse Tailored for the AI Era
- meet-undatas-io-v3-the-ai-ready-data-platform-reimagined-faster-smarter-and-more-accessible-than-ever
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- IBM-Docling-s-Upgrade-A-Fresh-Assessment-of-Intelligent-Document-Processing-Capabilities
- Can-Undatasio-Really-Deliver-Superior-PDF-Parsing-Quality-Sample-Based-Evidence-Speaks
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox