LlamaParse: Revolutionizing Document Parsing - A Deep Dive into Its Wonders and Weaknesses


Introduction
In the ever-expanding digital landscape, the ability to efficiently process and extract valuable information from complex documents has become a make-or-break factor for businesses, researchers, and data enthusiasts alike. Enter LlamaParse, a game-changing document parsing library developed by LlamaIndex that claims to transform the way we handle PDFs, PPTs, and other document formats. But does it truly live up to the hype?
Product Overview
LlamaParse comes with a promise to simplify the arduous task of parsing embedded objects such as tables and figures within documents, a challenge that has long plagued the data-handling community. With its seamless integration into the LlamaIndex framework, it aims to offer a one-stop solution for those looking to create Retrieval-Augmented Generation (RAG) applications on top of PDF documents. But how well does it perform in real-world scenarios? Can it accurately interpret and extract information from documents with complex layouts, multilingual content, and intricate visual elements?
Evaluation Objectives
In this in-depth review, we’ll put LlamaParse through its paces. We’ll explore its capabilities in handling different document types, from financial reports filled with complex tables to academic papers laden with mathematical formulas and multilingual text. We’ll also uncover its potential limitations, such as how it fares with scanned documents or documents with non-standard formatting. All results showcased in this evaluation are derived from its Premium parsing mode, which unlocks enhanced capabilities for extracting data from PDFs, and other formats.
Whether you’re an AI enthusiast eager to explore the latest in document-parsing technology, a data analyst constantly grappling with unstructured data, or a professional seeking a more effective way to manage and extract insights from documents, this review is for you. So, fasten your seatbelts as we embark on this journey to discover the true potential of LlamaParse.
Highlights Analysis
-
Efficient Text Parsing
- LlamaParse showcases an outstanding performance in text extraction from various PDF documents. It adeptly handles both simple text-only PDFs and complex files with mixed elements like images and tables. The tool maintains the correct reading order of recognized text, ensuring seamless content analysis and retrieval. For example, in academic research papers, it accurately extracts paragraphs, headings, and subheadings, enabling users to quickly navigate and understand the document structure.
-
Multilingual Text Parsing Support
- The tool demonstrates remarkable multilingual capabilities, proficiently recognizing and parsing texts in languages such as Spanish, French, German, and those with complex character sets like Chinese, Japanese, and Korean. This makes LlamaParse a valuable asset for global enterprises, international research projects, and multilingual data services, streamlining cross-cultural document processing and analysis.
Limitations Analysis
-
Weak Complex Table Parsing
- LlamaParse struggles significantly with complex tables, especially those featuring merged cells or intricate headers. Table headers are frequently misidentified, leading to incorrect data mapping, and cell content may be incomplete or jumbled. In financial reports or scientific datasets with hierarchical structures, the tool often fails to accurately capture relationships, resulting in unreliable analysis.
-
Ineffective Scanned Document Parsing
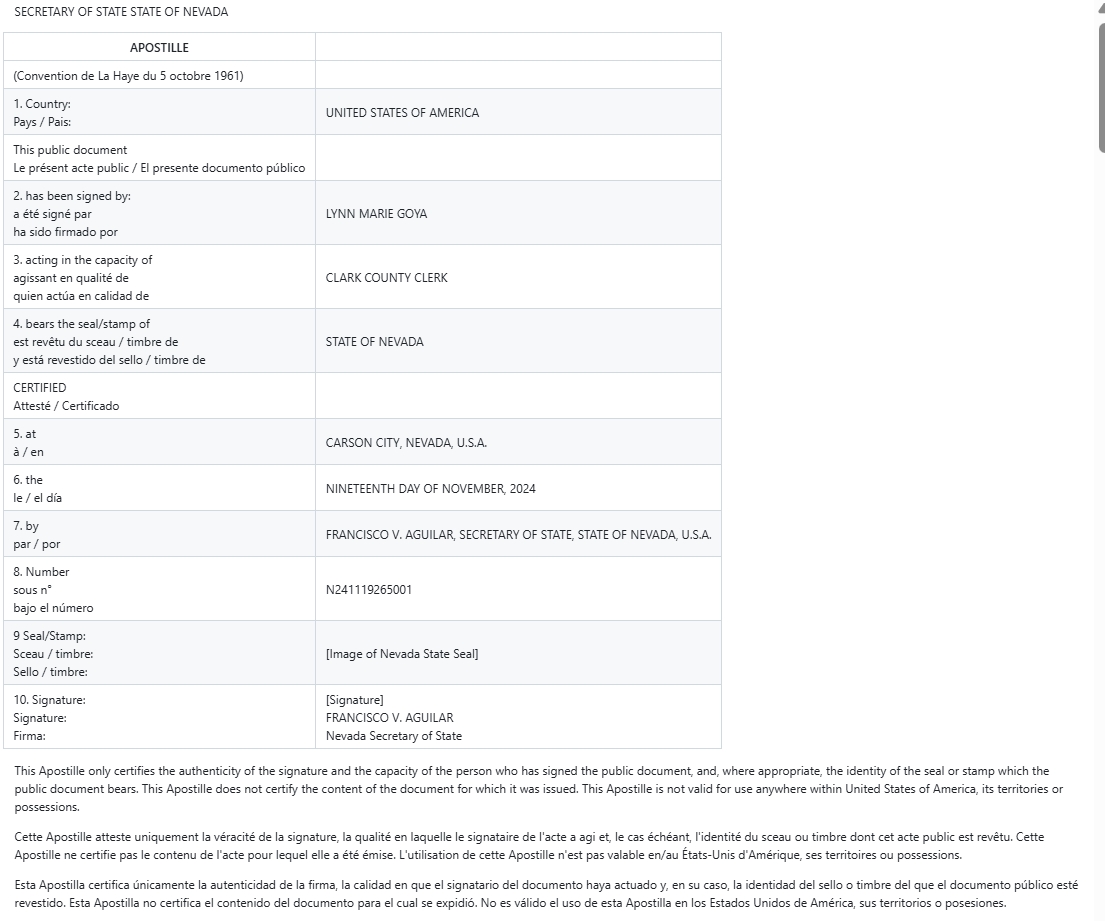
- Scanned PDF documents pose multiple critical challenges for LlamaParse. Formula recognition accuracy drops drastically, with complex equations often rendered incomplete or misinterpreted due to reliance on image-based OCR. Additionally, table reconstruction from scanned tables is highly unreliable; headers are frequently lost, cell boundaries are misaligned, and data extraction errors are common. Even with standard scanned reports, the tool struggles to reproduce table structures accurately, making it unsuitable for digitizing legacy or non-editable documents.
Functional Testing
The main focus is on accuracy testing. A diverse set of PDF documents—including those with complex layouts, mathematical formulas, tables, and multilingual content—were selected to assess LlamaParse’s recognition accuracy. Particular attention was paid to its performance in handling special characters, structured elements, and scanned vs. editable document formats.
1. Text Extraction Test
Editable PDF Documents LlamaParse demonstrated high accuracy in extracting text from editable PDFs. The tool preserved the correct reading order and accurately captured text across various font styles and sizes. Minor issues arose only in documents with nested columns or overlapping text elements, but overall integrity remained intact.
Sample Document

Rendered Output
Scanned PDF Documents Scanned PDFs posed significant challenges for LlamaParse. Text recognition accuracy dropped notably, especially in documents with low-resolution scans or faded ink. Missing characters, incorrect word segmentation, and misinterpretation of handwritten elements were common issues.
Sample Document

Rendered Output
2. Multilingual Test
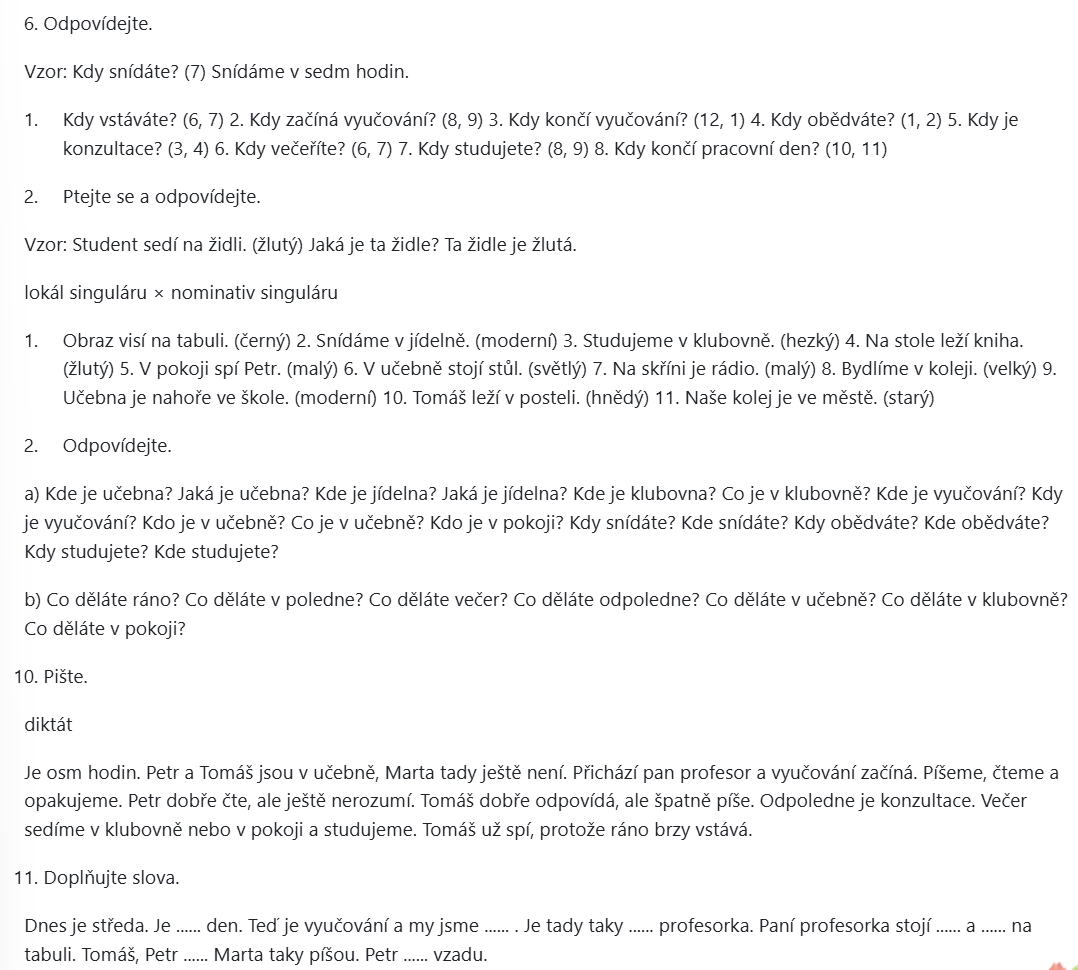
In the multilingual samples, the recognition of Korean, Czech, Portuguese and Japanese is generally accurate. Handwritten text recognition in these languages is also possible, although the accuracy is slightly lower compared to printed text.
Sample Document - Korean

Rendered Output

Sample Document - Czech

Rendered Output
Sample Document - Portuguese

Rendered Output

Sample Document - Japanese
Rendered Output

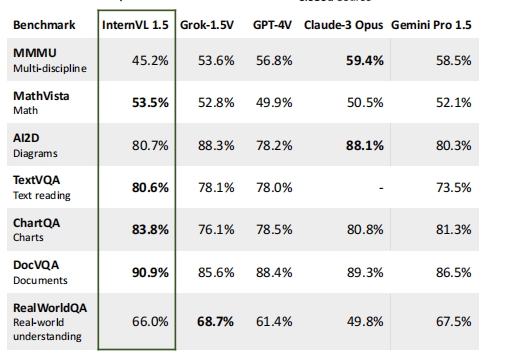
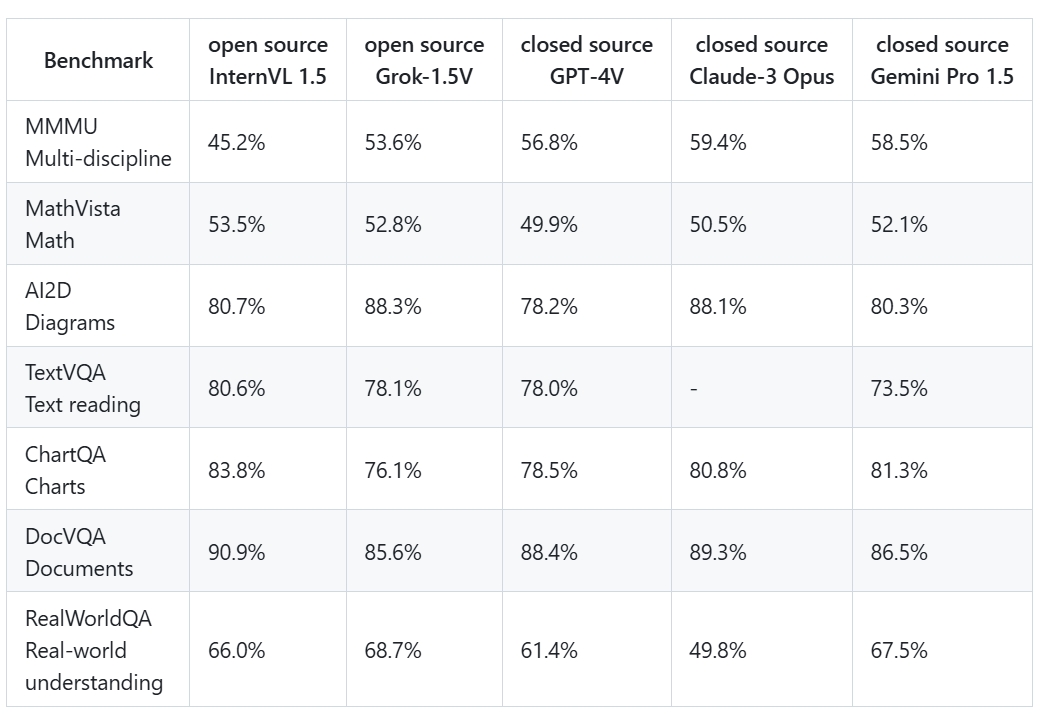
3. Table Recognition Test
For simple, grid-based tables, olmOCR identified the structure correctly and extracted most cell data. However, exponential values or complex formatting within cells (e.g., currency symbols with subscripts) were often misparsed. Complex tables with merged cells, hierarchical headers, or irregular layouts posed major limitations. Headers were frequently misaligned or incomplete, and cell content from merged sections was jumbled or lost.
Sample Table
Rendered Output
Sample Table
Rendered Output
Sample Table
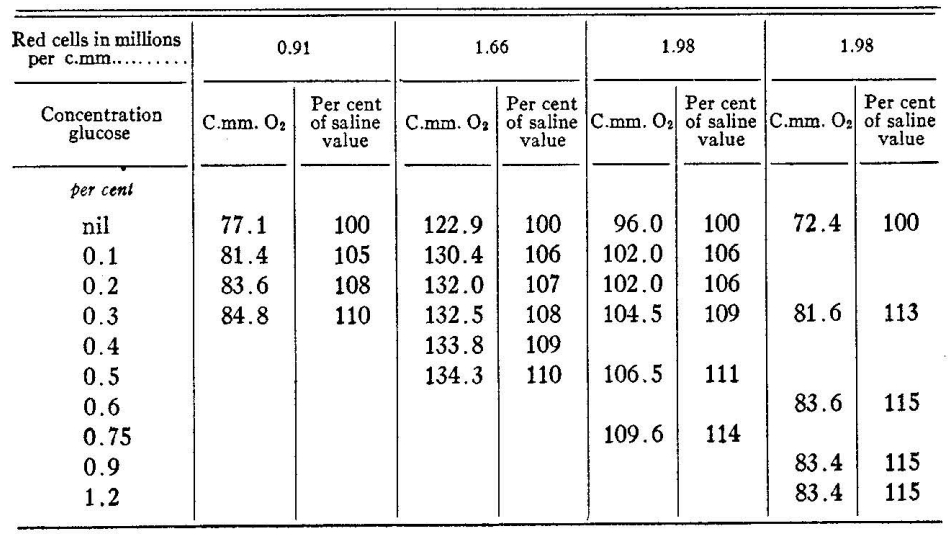
Rendered Output
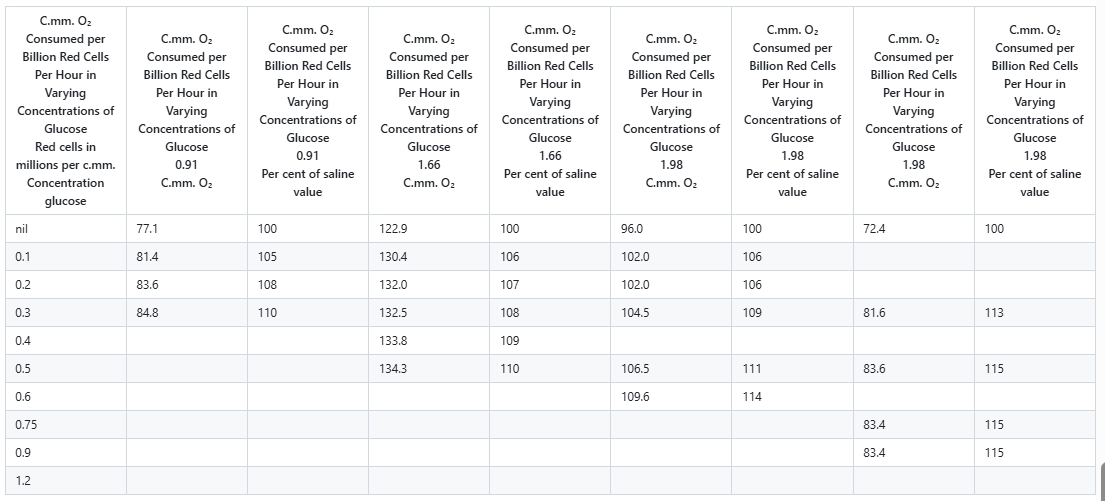
Sample Document with Complex Table
Rendered Output
4. Formula Recognition Test
LlamaParse demonstrated notable proficiency in parsing formulas from editable PDF documents. When handling text-based equations, it accurately identified symbols, exponents, and complex functions, ensuring faithful reconstruction of mathematical expressions. Even formulas with nested operators or Greek letters were parsed with high precision, making it a reliable choice for structured documents.
However, the tool faced significant challenges with scanned PDF documents. In cases where formulas were embedded within images, recognition accuracy dropped substantially. This limitation highlights the need for additional preprocessing or alternative solutions when dealing with non-editable, image-based content.
Sample Document with Formulas

Rendered Output


Sample Document with Formulas

Rendered Output


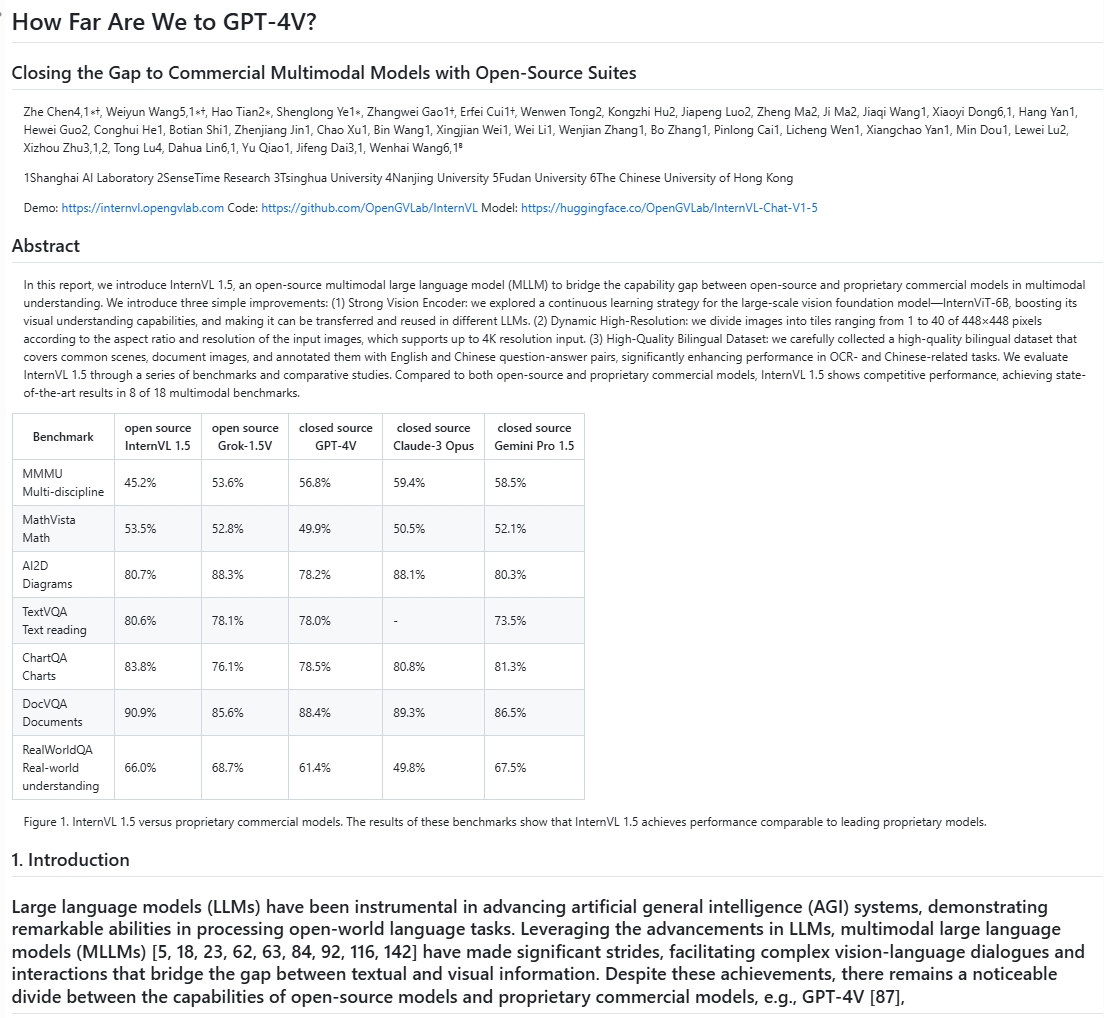
Comprehensive Evaluation: LlamaParse showcases strong text and formula extraction capabilities for editable documents and printed multilingual text. However, it struggles significantly with scanned PDFs, complex tables. Improvements in these areas would greatly enhance its utility across diverse real-world applications.
📖See Also
- In-depth Review of Mistral OCR A PDF Parsing Powerhouse Tailored for the AI Era
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Evaluation-of-Chunkrai-Platform-Unraveling-Its-Capabilities-and-Limitations
- IBM-Docling-s-Upgrade-A-Fresh-Assessment-of-Intelligent-Document-Processing-Capabilities
- Is-SmolDocling-256M-an-OCR-Miracle-or-Just-a-Pretty-Face-An-In-depth-Review-Reveals-All
- Can-Undatasio-Really-Deliver-Superior-PDF-Parsing-Quality-Sample-Based-Evidence-Speaks
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox