Comparing Top 3 Python Libraries for Document Intelligence and Data Extraction: A Comprehensive Guide


In the digital age, AI documents are ubiquitous, holding crucial information for various tasks. But when it comes to unlocking that data with Python, choosing the right library for document intelligence can be a maze. Fear not! This blog is your compass, delving into the top three Python libraries for document data extraction – PyPDF2, pdfplumber, and PDFMiner – to help you effortlessly navigate the complex world of AI document extraction, manipulation, and analysis.
1 Common Requirements
When it comes to processing AI documents, there are several common requirements:
- Text Extraction: Extract text from AI documents for subsequent analysis and processing.
- Table Extraction: Some AI documents contain structured data, especially tables, which need to be automatically extracted.
- Batch Processing: Handle hundreds or even thousands of AI documents at once without manual intervention.
- Merging or Splitting Documents: Sometimes, we need to combine multiple AI documents into one or split specific pages from a large file.
- Data Crawling: Download AI documents from web pages and identify and extract certain data.
2 Showdown of Parsing Libraries
Next, we’ll make a detailed comparison of the three mainstream libraries in terms of their functions, advantages, and disadvantages to help you find the most suitable tool for document intelligence.
PyPDF2: A Veteran Player with Simplicity and Versatility
Advantages
- High Usability: PyPDF2 is a well - established library for document processing with a straightforward API, making it extremely easy to get started and ideal for beginners.
- Comprehensive Basic Functions: It can not only parse text from AI documents but also merge, split, encrypt, and decrypt documents.
- Cross - Platform Support: Applicable to mainstream platforms like Windows, Linux, and MacOS.
Disadvantages
- Struggles with Complex Documents: While it’s great for simple text extraction, when dealing with AI documents with complex layouts (such as multi - columns, tables, etc.), the extracted text may be out of order or messy.
- No Table Extraction Support: PyPDF2 doesn’t handle tables in AI documents well.
Code Example: Extracting Text from AI Documents with PyPDF2
import PyPDF2
# Open the AI document file
with open("example.pdf", "rb") as file:
# Create a document reader
reader = PyPDF2.PdfReader(file)
# Initialize a text container
text = ""
# Traverse each page and extract text
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
print(text)
Running this code gives you the text content of the entire AI document. It’s simple, fast, and handy. However, note that if the document is too complex, the extraction results might not be satisfactory.
pdfplumber: A Great Helper for Fine - Grained Text and Table Extraction
Advantages
- Text and Table Extraction in One Go: The standout feature of pdfplumber is its ability to extract not only text but also efficiently handle tables in AI documents. It can even capture images on the page.
- Fine - Grained Control: pdfplumber offers detailed control over the document page structure, suitable for scenarios that require precise extraction, such as financial statements, contracts, and questionnaires.
Disadvantages
- Relatively Slow: Due to its ability to parse more complex content, it’s a bit slower compared to other libraries.
- Steeper Learning Curve: Its powerful features mean you’ll need to spend more time learning how to use it correctly, especially for table extraction.
Code Example: Extracting Text and Tables from AI Documents with pdfplumber
import pdfplumber
# Open the AI document file
with pdfplumber.open("example.pdf") as pdf:
# Extract the content of the first page
first_page = pdf.pages[0]
# Extract text
text = first_page.extract_text()
print("Text content:")
print(text)
# Extract tables
tables = first_page.extract_tables()
print("Table content:")
for table in tables:
for row in table:
print(row)
In this code, we’ve extracted both text and tables from an AI document. pdfplumber excels at handling tables and is perfect for scenarios that require parsing structured data.
PDFMiner: A Hardcore Tool for Deep Document Parsing
Advantages
- Powerful Parsing Capability: PDFMiner has an extremely powerful parsing function. It can recognize complex layouts in AI documents, including text, fonts, and paragraphs. It doesn’t just extract content but can also restore the document’s structure and hierarchy.
- Fine - Grained Extraction: It can extract text at different granularities, such as characters, lines, and paragraphs, suitable for scenarios that require in - depth analysis of the document.
Disadvantages
- Complex to Use: Due to its powerful features, its API is relatively complex, resulting in a higher learning cost for beginners.
- Slow Speed: As it needs to perform deep parsing, PDFMiner is slow when dealing with complex AI documents.
Code Example: Extracting Text from AI Documents with PDFMiner
from pdfminer.high_level import extract_text
# Extract text
text = extract_text("example.pdf")
print(text)
Compared to PyPDF2 and pdfplumber, the code for PDFMiner seems relatively simpler, but it does a lot more behind the scenes, and the parsed text usually has a better structure, especially for AI documents with multi - column text and complex formats.
3 Library Function Showdown
Let’s have a head - to - head comparison to see the advantages and disadvantages of these three libraries more intuitively:
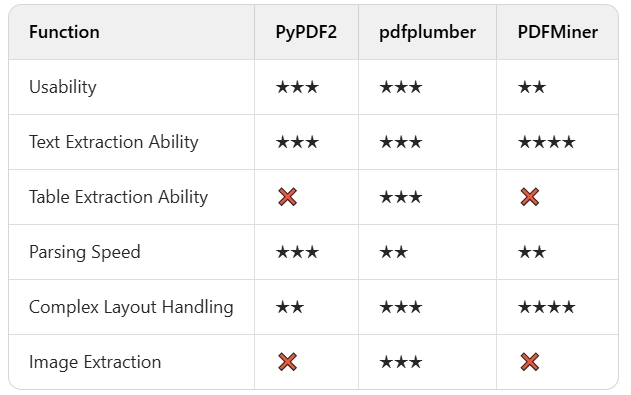
Conclusion:
- If you’re a beginner in AI document processing and need to get started quickly, PyPDF2 is the best choice.
- If you require precise extraction of text and tables from AI documents, especially when dealing with documents with structured data, pdfplumber is undoubtedly your top pick.
- If your AI documents are highly complex, with multi - column text or complex layouts, and you want to restore the document’s structure as much as possible, PDFMiner is the way to go.
4 Practical Application
Let’s say we now have a bunch of AI documents and urgently need to extract the text content and perform batch processing. Next, we’ll demonstrate how to use the above libraries to batch process AI documents and save the results to text files.
Batch Processing Code Example:
import os
import PyPDF2
def extract_text_from_documents(directory):
for filename in os.listdir(directory):
if filename.endswith(".pdf"):
filepath = os.path.join(directory, filename)
with open(filepath, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
# Save the extracted text
with open(f"{filename}.txt", "w", encoding="utf - 8") as text_file:
text_file.write(text)
print(f"Extracted: {filename}")
extract_text_from_documents("document_folder")
This simple script traverses all the AI documents in a folder, extracts the text, and saves it as a.txt file. You can choose to replace PyPDF2 with different document processing libraries according to your needs.
5 Summary
Through this article, we’ve made a detailed comparison of the three commonly used Python libraries for document intelligence and data extraction: PyPDF2, pdfplumber, and PDFMiner. Each has its own strengths and is suitable for different scenarios. You can choose the most appropriate library based on your specific requirements and quickly get started with the code examples provided in this article.
In the world of technology, tools are our companions, and what matters most is how to use them flexibly. Whether it’s simple text extraction from AI documents or complex table and image parsing, Python has got you covered.
Hopefully, through this post, you’ve gained a deeper understanding of Python for document intelligence and data extraction. Future complex AI documents will no longer be a challenge for you.
📖See Also
- Demystifying-Unstructured-Data-Analysis-A-Complete-Guide
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Comparison-of-API-Services-Graphlit-LlamaParse-UndatasIO-etc-for-PDF-Extraction-to-Markdown
- Comparing-Top-3-Python-PDF-Parsing-Libraries-A-Comprehensive-Guide
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Assessment-of-Microsofts-Markitdown-series2-Parse-PDF-files
- Assessment-of-MicrosoftsMarkitdown-series1-Parse-PDF-Tables-from-simple-to-complex
- AI-Document-Parsing-and-Vectorization-Technologies-Lead-the-RAG-Revolution
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox