Improving the Response Quality of RAG Systems: High-Quality Enterprise Document Parsing


Large Language Models (LLMs) have demonstrated powerful capabilities in generating natural language texts. However, their training data usually comes from public and extensive data sources, which means that when faced with the private data of specific enterprises, they may not be able to accurately generate relevant answers or information. One feasible approach is to use these professional data to fine-tune the LLMs, but this usually has very high requirements in terms of technology and cost. In contrast, the Retrieval-Augmented Generation (RAG) system offers a more economical and efficient solution. It attaches relevant private domain data after the user’s original question and combines it with the general LLM for analysis and summary. In this way, the RAG system provides more accurate information for the LLM through retrieval enhancement, greatly improving the final response effect, as shown in the following figure:
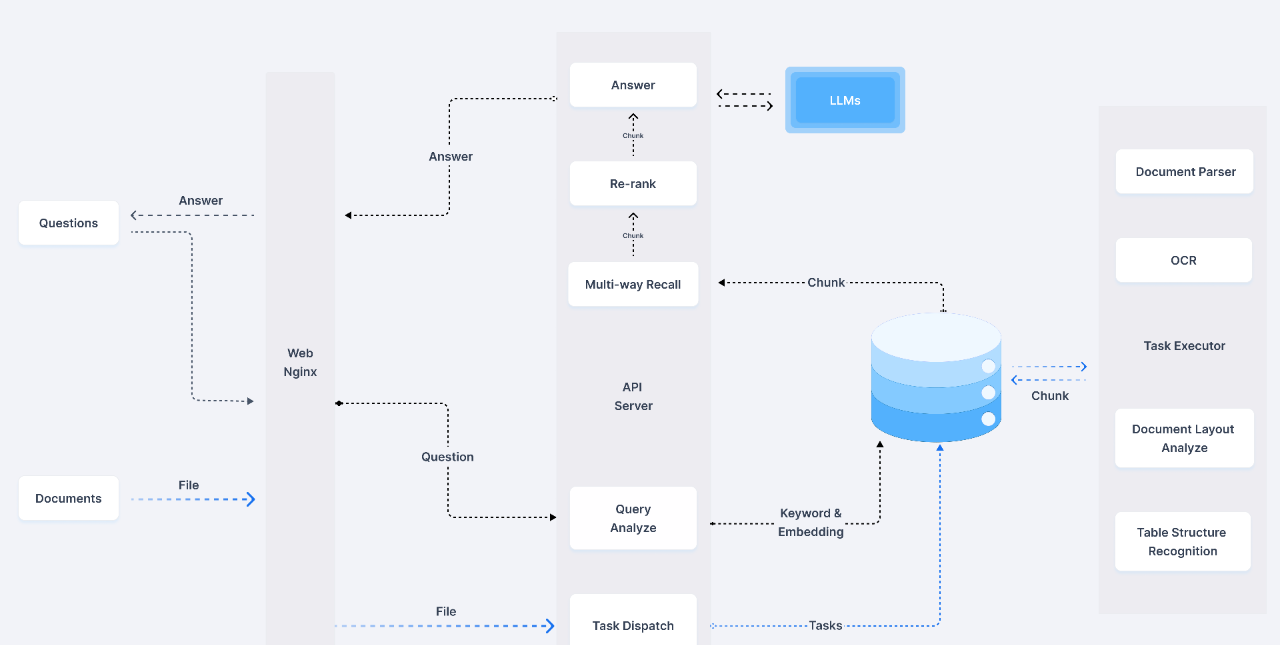
The Importance of Enterprise Private Data in Forming Knowledge
Enterprise private data is usually stored in the form of documents, including technical manuals, policy documents, customer files, research reports, etc. These documents carry the core knowledge of the enterprise and are the foundation of enterprise operations. By converting these documents into retrievable structured data, the RAG system can quickly access and utilize this data when needed, thus providing immediate references for the LLM.
This process can:
- Improve the professionalism of responses: Ensure that the response content meets the professional requirements and standards of the enterprise.
- Enhance data security: Avoid the leakage of sensitive information through the closed retrieval of private data.
- Support dynamic updates: As documents are updated, the RAG system can continuously refresh its knowledge base to ensure the timeliness of response content.
The Diversity of Enterprise Private Data Storage Media
Enterprise private data is usually stored in various media forms, which carry the key knowledge and information within the company. Common document media include:
- Text documents (such as TXT, Markdown)
- Office documents (such as DOC, DOCX, PPT, XLSX)
- PDF files
- Databases (such as SQL, NoSQL)
- Multimedia files (such as images, audio, video)
- Proprietary format files (such as design drawings, technical specifications, etc.)
The data in these document media is often structured, semi-structured, or unstructured. Therefore, parsing and reading this data is crucial for realizing the automated retrieval and generation of enterprise knowledge.
Parsing Based on DOC and DOCX Documents
DOC and DOCX are file formats of Microsoft Word, which are widely used in the writing and storage of various enterprise documents. The process of parsing these document types is relatively complex because they not only contain text but may also embed various complex elements, such as tables, images, hyperlinks, headers and footers, comments, revision histories, etc. The parsing and reading of these elements involve technical challenges at multiple levels.
1. Parsing of Text Content
- Paragraphs and Headings: The internal structure of DOCX files is usually represented by XML, and each paragraph and heading has a clear label. When parsing, it is necessary to identify these labels to extract text structure information at different levels.
- Character Styles: Style information such as font, size, and color can also be obtained by parsing XML, which is essential for retaining the format of the original document.
from docx import Document
def parse_docx_text(file_path):
doc = Document(file_path)
for para in doc.paragraphs:
print(f"{para.text}")
2. Parsing of Table Content
- Table Structure: Tables are very common in enterprise documents, such as financial statements, technical specification tables, etc. When parsing tables, it is necessary to accurately identify the data in each cell and maintain its position within the table.
- Complex Tables: Those including merged cells, nested tables, etc. are more complicated to parse and require special processing logic.
def parse_docx_tables(file_path):
doc = Document(file_path)
for table in doc.tables:
for row in table.rows:
print([cell.text for cell in row.cells])
3.Parsing of Images and Other Embedded Objects
- Images: The images that may be contained in DOCX documents can be extracted by parsing the <w:drawing> tags embedded in the document.
- Other Objects: This includes charts, formulas, SmartArt, etc. Since these objects may be stored in binary format, specific libraries or APIs need to be used for parsing and processing.
def extract_images_from_docx(docx_path):
doc = Document(docx_path)
for rel in doc.part.rels.values():
if "image" in rel.target_ref:
print(f"extract image: {rel.target_ref}")
4. Extraction of Metadata
- Metadata such as the author, creation date, and revision history is included in the properties of the document and is very important for document version control and traceability management. This information can be extracted by accessing the docProps of the DOCX file.
5. Processing Batch Documents
- In enterprises, it is a common requirement to process a large number of DOCX documents in batches. At this time, parallel processing technologies need to be considered to improve the parsing efficiency, and semantic segmentation of the parsed content can also be considered to optimize the subsequent RAG applications.
import os
from concurrent.futures import ProcessPoolExecutor
def process_docx_files(directory):
docx_files = [f for f in os.listdir(directory) if f.endswith('.docx')]
with ProcessPoolExecutor() as executor:
for _ in executor.map(parse_docx_text, docx_files):
pass
Parsing and processing enterprise DOC and DOCX documents is an important step for the RAG system. By accurately extracting the structured and unstructured information in the documents, semantic segmentation and the construction of the knowledge base can be better achieved. These processing steps not only ensure the effective utilization of enterprise private data but also greatly improve the generation quality and retrieval accuracy of the RAG system.
Next, we will analyze in detail the DOCX parsing method of the DocxParser class written in Python code.
Parsing Method Code:
def __call__(self, filename, binary=None, from_page=0, to_page=100000):
self.doc = Document(
filename) if not binary else Document(BytesIO(binary))
pn = 0
lines = []
last_image = None
for p in self.doc.paragraphs:
if pn > to_page:
break
if from_page <= pn < to_page:
if p.text.strip():
if p.style and p.style.name == 'Caption':
former_image = None
if lines and lines[-1][1] and lines[-1][2] != 'Caption':
former_image = lines[-1][1].pop()
elif last_image:
former_image = last_image
last_image = None
lines.append((self.__clean(p.text), [former_image], p.style.name))
else:
current_image = self.get_picture(self.doc, p)
image_list = [current_image]
if last_image:
image_list.insert(0, last_image)
last_image = None
lines.append((self.__clean(p.text), image_list, p.style.name))
else:
if current_image := self.get_picture(self.doc, p):
if lines:
lines[-1][1].append(current_image)
else:
last_image = current_image
for run in p.runs:
if 'lastRenderedPageBreak' in run._element.xml:
pn += 1
continue
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
pn += 1
new_line = [(line[0], reduce(concat_img, line[1]) if line[1] else None) for line in lines]
tbls = []
for tb in self.doc.tables:
html= "<table>"
for r in tb.rows:
html += "<tr>"
i = 0
while i < len(r.cells):
span = 1
c = r.cells[i]
for j in range(i+1, len(r.cells)):
if c.text == r.cells[j].text:
span += 1
i = j
i += 1
html += f"<td>{c.text}</td>" if span == 1 else f"<td colspan='{span}'>{c.text}</td>"
html += "</tr>"
html += "</table>"
tbls.append(((None, html), ""))
return new_line, tbls
def __call__(self, filename, binary=None, from_page=0, to_page=100000):
self.doc = Document(filename) if not binary else Document(BytesIO(binary))
pn = 0
lines = []
last_image = None
- Function Entry: __call__ is a magic method that enables class instances to be called like functions. It accepts the file name, binary data, starting page, and ending page as input parameters and loads the document into self.doc. If binary data is provided, it will be processed using BytesIO.
- Page Number Control: The from_page and to_page parameters allow us to control from which page of the document to start parsing and to which page to end. This is very useful when dealing with large documents and can avoid memory overload caused by loading the entire document at once.
for p in self.doc.paragraphs:
if pn > to_page:
break
if from_page <= pn < to_page:
if p.text.strip():
if p.style and p.style.name == 'Caption':
former_image = None
if lines and lines[-1][1] and lines[-1][2] != 'Caption':
former_image = lines[-1][1].pop()
elif last_image:
former_image = last_image
last_image = None
lines.append((self.__clean(p.text), [former_image], p.style.name))
else:
current_image = self.get_picture(self.doc, p)
image_list = [current_image]
if last_image:
image_list.insert(0, last_image)
last_image = None
lines.append((self.__clean(p.text), image_list, p.style.name))
else:
if current_image := self.get_picture(self.doc, p):
if lines:
lines[-1][1].append(current_image)
else:
last_image = current_image
- Paragraph Traversal: The for p in self.doc.paragraphs loop traverses all the paragraphs of the document. The variable pn records the current page number and controls the parsing within the page number range.
- Text and Image Processing:
- Paragraph Text: If the paragraph has text content and belongs to the specified page number range, the text will be extracted and cleaned (self.__clean).
- Image Processing: If the paragraph style is “Caption” (caption text), it will be determined whether it is associated with an image. The associated image will be extracted and added to the lines list. For ordinary paragraphs, the extracted image will also be added to the lines list after extraction.
for run in p.runs:
if 'lastRenderedPageBreak' in run._element.xml:
pn += 1
continue
if 'w:br' in run._element.xml and 'type="page"' in run._element.xml:
pn += 1
- Page Break Handling: The for run in p.runs loop traverses each run block in the paragraph, detects whether there is a page break or a manual page break, and increases the page number count pn accordingly.
new_line = [(line[0], reduce(concat_img, line[1]) if line[1] else None) for line in lines]
- Data Integration: The parsed line data (text + images) will be merged and processed. The reduce(concat_img, line[1]) function will merge multiple images in the same line.
tbls = []
for tb in self.doc.tables:
html = "<table>"
for r in tb.rows:
html += "<tr>"
i = 0
while i < len(r.cells):
span = 1
c = r.cells[i]
for j in range(i+1, len(r.cells)):
if c.text == r.cells[j].text:
span += 1
i = j
i += 1
html += f"<td>{c.text}</td>" if span == 1 else f"<td colspan='{span}'>{c.text}</td>"
html += "</tr>"
html += "</table>"
tbls.append(((None, html), ""))
return new_line, tbls
- Table Parsing: Traverse each table in the document, extract the table content and convert it into HTML format. In the case where the cell contents are the same and consecutive, use colspan to merge the cells.
- Result Return: Finally, the function returns the combination of the extracted text and images (new_line), as well as the tables converted into HTML format (tbls).
This code demonstrates how to accurately extract the core information of a document, including paragraphs, images, and tables. By controlling the page number range for parsing, large documents can be processed efficiently. And for documents with both text and images, this code is especially valuable.
In the RAG system, such parsing steps can help enterprises transform unstructured documents into structured data. Through further semantic segmentation and vectorization processing, it can provide high-quality input for subsequent retrieval and generation. This code not only shows the technical implementation of document content extraction but also indicates the importance of precise text and image association processing for the RAG system in a complex document environment.
📖See Also
- Demystifying-Unstructured-Data-Analysis-A-Complete-Guide
- Cracking-Document-Parsing-Technologies-and-Datasets-for-Structured-Information-Extraction
- Comparison-of-API-Services-Graphlit-LlamaParse-UndatasIO-etc-for-PDF-Extraction-to-Markdown
- Comparing-Top-3-Python-PDF-Parsing-Libraries-A-Comprehensive-Guide
- Assessment-Unveiled-The-True-Capabilities-of-Fireworks-AI
- Assessment-of-Microsofts-Markitdown-series2-Parse-PDF-files
- Assessment-of-MicrosoftsMarkitdown-series1-Parse-PDF-Tables-from-simple-to-complex
- AI-Document-Parsing-and-Vectorization-Technologies-Lead-the-RAG-Revolution
Subscribe to Our Newsletter
Get the latest updates and exclusive content delivered straight to your inbox